Le Data Engineering industrialise la donnée : il transforme des sources hétérogènes en jeux de données fiables, traçables et exploitables pour l’analytique, le produit et l’IA.
Le Data Engineering désigne l’ensemble des pratiques, architectures et outils qui permettent de collecter, fiabiliser, transformer, documenter et servir des données de manière industrielle, afin qu’elles soient utilisables par le reporting, l’analytique, les produits numériques et les systèmes d’IA.
L’objectif n’est pas de “déplacer des données” pour qu’elles existent quelque part, mais de garantir un résultat exploitable dans le temps : définitions stables, fraicheur mesurée, qualité contrôlée, traçabilité claire, droits d’accès corrects, et coûts sous contrôle.
Le rôle a changé parce que les usages ont changé. Un pipeline “qui tourne” ne suffit plus : la donnée doit être fiable (sinon les décisions et les modèles IA se trompent), traçable (sinon personne ne peut expliquer une métrique), sécurisée (sinon le risque explose), et opérable (sinon les équipes passent leur temps à “réparer” au lieu d’améliorer).
Le Data Engineering est à la donnée ce que l’ingénierie logicielle est à une application : il transforme une accumulation de scripts et d’outils en un système exploitable, testable, évolutif et gouverné.
Trois dynamiques expliquent la centralité du Data Engineering : (1) la multiplication des sources et des formats, (2) l’exigence de fraicheur (données disponibles plus vite), (3) la pression IA qui rend la gouvernance et la qualité non négociables.
La plupart des organisations combinent aujourd’hui des bases transactionnelles (produit), des CRM, des outils marketing, de la finance, du support, des logs, et des événements temps réel. Cette diversité crée des problèmes structurels : identifiants incohérents, schémas instables, règles métier implicites, historiques partiels, et difficultés à reproduire un calcul dans le temps. Le Data Engineering apporte une discipline : capturer, normaliser, historiser, et produire des datasets “consommables” avec des contrats stables.
Une annonce IBM cite une enquête Gartner : 63% des organisations n’ont pas, ou ne savent pas si elles ont, les bonnes pratiques de gestion de données pour l’IA. Cette statistique illustre un point simple : l’IA pousse la donnée hors du périmètre BI traditionnel, vers des usages plus sensibles (documents, contenus, données non structurées, traces), où la gouvernance et la traçabilité deviennent indispensables. [Source]
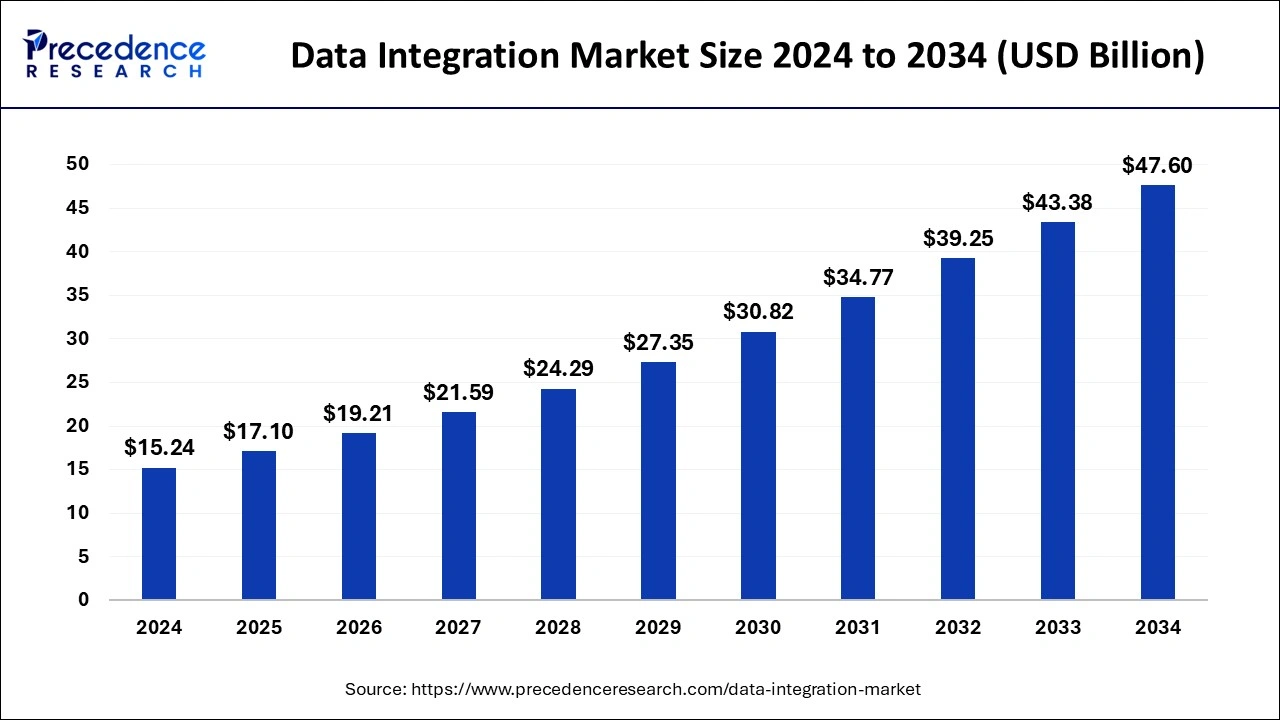
Les marchés adjacents (intégration, entrepôts cloud) donnent une lecture macro. Precedence Research indique que le marché mondial de l’intégration de données est évalué à 17,10 Md$ en 2025 et devrait passer à 19,21 Md$ en 2026, avec une estimation à 51,82 Md$ d’ici 2035 (CAGR 11,72% sur 2026–2035). [Source]
Mordor Intelligence affiche publiquement une estimation du marché “cloud data warehouse” à 14,94 Md$ en 2026 et une projection à 49,12 Md$ d’ici 2031 (CAGR 26,86% sur 2026–2031). [Source]
IndustryARC publie une projection différente (périmètre et méthodologie potentiellement distincts) : “Cloud Data Warehouse Market” à 39,1 Md$ d’ici 2026 après une croissance à 31,4% de CAGR sur 2021–2026. [Source]
Des rapports différents peuvent produire des valeurs éloignées sans que l’un soit “faux” : les écarts viennent des définitions de marché, des segments inclus, et des régions. L’intérêt opérationnel est de constater une tendance durable : consolidation des outils, migration cloud, et montée de l’exigence de gouvernance portée par l’IA.
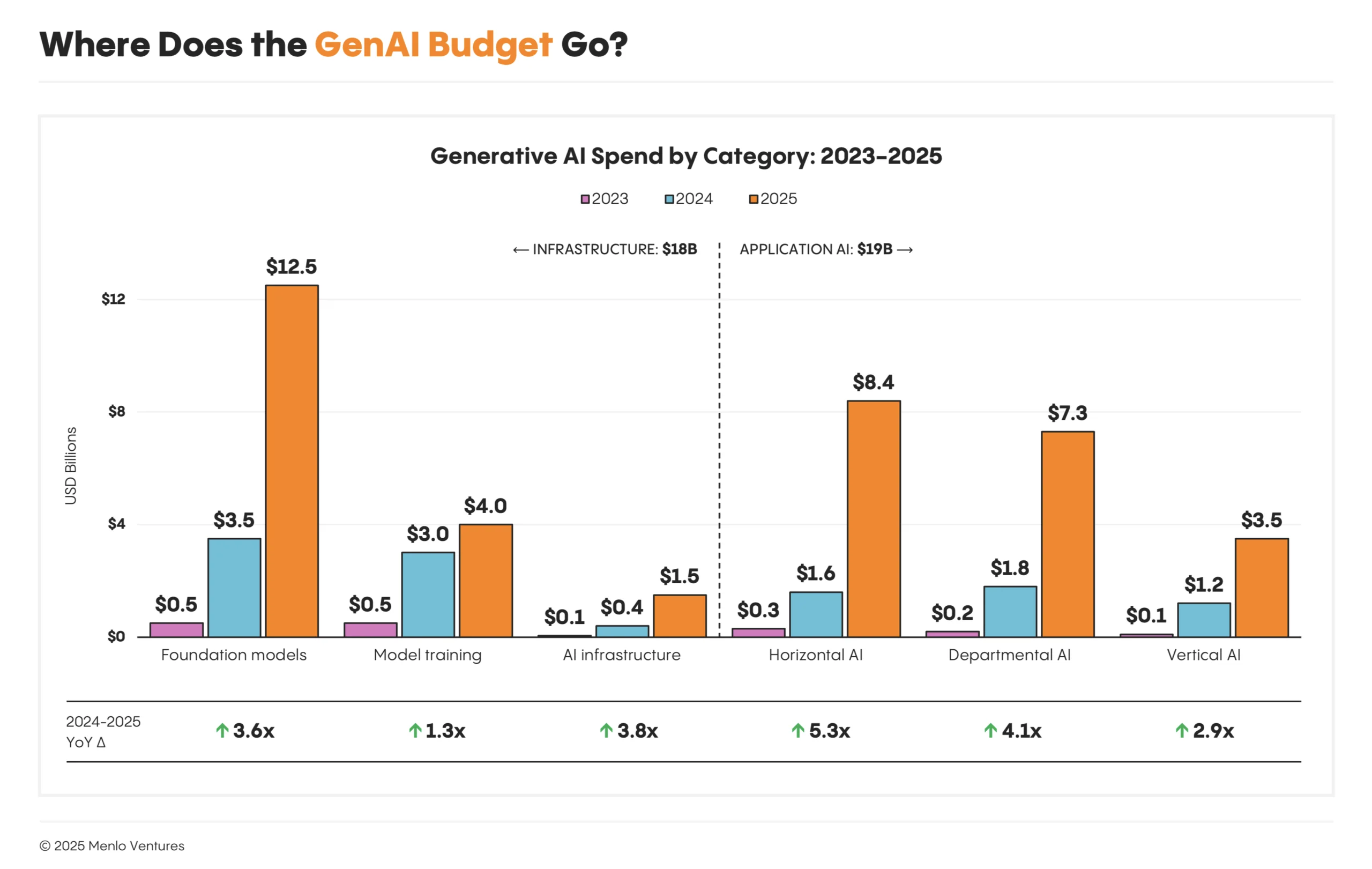
Menlo Ventures indique que les entreprises ont dépensé 37 Md$ en IA générative en 2025, contre 11,5 Md$ en 2024 (x3,2 sur un an). Le rapport mentionne également que 76% des cas d’usage IA sont achetés plutôt que construits, et que 47% des “AI deals” vont en production (vs 25% pour le SaaS traditionnel). Dans ce contexte, la capacité à intégrer rapidement des données fiables, gouvernées et observables devient un avantage concurrentiel. [Source]
Le data engineer conçoit et opère des systèmes qui rendent la donnée disponible et fiable. Les missions varient selon la structure (équipe data centralisée, équipes produit autonomes, data platform dédiée), mais un noyau commun existe : ingestion, transformation, fiabilité, observabilité, et gouvernance.
En production, les problèmes les plus coûteux sont rarement des erreurs “visibles” : ce sont des erreurs silencieuses (dérive de distribution, doublons, schéma modifié, suppression dans une source, changement de règle métier). Le data engineer doit pouvoir expliquer : d’où vient une métrique, pourquoi elle change, quelles transformations la composent, et qui sera impacté par un changement.
La fiabilité ne se résume pas à “zéro erreur”. Elle signifie : détecter vite, isoler l’impact, corriger proprement, rejouer l’historique si nécessaire, et prévenir la récidive.
Le Data Engineering se situe entre plusieurs mondes. L’interface la plus difficile est souvent organisationnelle : aligner les définitions entre équipes (finance, produit, marketing), stabiliser les schémas produits par des équipes applicatives, et faire respecter des règles de gouvernance sans ralentir l’innovation.
| Rôle | Focus principal | Livrables typiques |
|---|---|---|
| Data Engineer | Pipelines, ingestion, fiabilité, serving data | CDC/streaming, zones bronze/silver/gold, orchestration, monitoring |
| Analytics Engineer | Modèle sémantique et règles métier | Modèles de transformation (ex. dbt), tests métier, documentation |
| Data Platform Engineer | Socle self-service, sécurité, standards | IaC, templates CI/CD, catalogues, guardrails, politiques d’accès |
Une architecture data moderne vise un objectif simple : fournir des données exploitables, au bon niveau de fraicheur, avec un niveau de confiance suffisant pour supporter la décision, l’automatisation et l’IA. En pratique, cet objectif se heurte à des contraintes très concrètes : hétérogénéité des sources, volumes croissants, schémas changeants, exigences de conformité, arbitrages de coûts, et attentes différentes selon les consommateurs de données.
Le Data Engineering ne repose donc pas sur une architecture unique. Il s’appuie sur plusieurs modèles, choisis ou combinés selon les cas d’usage : traitement batch pour la robustesse et la simplicité, streaming pour la réactivité, lakehouse pour unifier stockage et analytique, et data mesh pour distribuer la responsabilité de la donnée dans les organisations complexes.
Le traitement batch consiste à déplacer et transformer les données à intervalles réguliers : toutes les heures, toutes les nuits, ou selon une fréquence métier adaptée. Malgré l’attrait du temps réel, le batch reste dominant dans de nombreuses organisations, pour une raison simple : il est souvent suffisant, moins coûteux et plus facile à exploiter.
Un pipeline batch bien conçu permet d’historiser proprement les données, de rejouer un traitement, d’isoler les incidents et de produire des tables analytiques stables. Pour les usages BI, le reporting financier, l’analyse produit quotidienne, la segmentation marketing ou les exports réglementaires, cette approche reste pertinente. Le vrai enjeu n’est pas d’abolir le batch, mais d’éviter qu’il se transforme en enchaînement opaque de scripts sans contrôle.
Le temps réel n’est pas une preuve de maturité. Une architecture batch fiable, documentée et gouvernée vaut souvent mieux qu’un pseudo-streaming fragile, coûteux et mal compris.
Le streaming traite les données au fil de l’eau ou par micro-lots très rapprochés. Il devient intéressant lorsque la donnée perd rapidement de sa valeur si elle n’est pas disponible immédiatement : détection de fraude, monitoring applicatif, personnalisation en session, alerting opérationnel, logistique, ou mise à jour quasi temps réel de certains indicateurs critiques.
Mais le streaming augmente aussi la complexité. Il faut gérer l’ordre des événements, les duplications, les retards, les reprises après incident, les offsets, les fenêtres temporelles, et les changements de schéma sans casser les consommateurs en aval. Autrement dit, le streaming est un accélérateur puissant, mais il impose une discipline supérieure.
Le lakehouse s’est imposé comme une réponse à une tension ancienne : d’un côté, les data lakes permettent d’absorber des volumes importants et des formats variés ; de l’autre, les entrepôts de données apportent gouvernance, performance analytique et structuration. Le lakehouse cherche à réunir ces avantages dans un même socle, grâce à des formats de tables ouverts, de la gestion transactionnelle, du versioning, et une meilleure interopérabilité entre moteurs.
Concrètement, cette approche rend possible une gestion plus cohérente des couches de données : zone brute, zone raffinée, zone de consommation. Elle facilite également certains scénarios hybrides, où les mêmes données servent à la fois aux tableaux de bord, aux explorations analytiques, aux jeux d’entraînement ML, ou à des pipelines RAG.
Le data mesh est souvent présenté comme un modèle architectural, mais son cœur est organisationnel. L’idée est de ne plus considérer la donnée comme un service purement centralisé, géré par une équipe isolée, mais comme un produit porté par les domaines métiers eux-mêmes. Chaque domaine devient responsable de la qualité, de la documentation et de l’exposition de ses jeux de données, tandis qu’une plateforme commune fournit les standards, l’outillage et les garde-fous.
Cette approche répond à une limite classique des équipes data centralisées : elles deviennent vite un goulot d’étranglement, accumulent des demandes contradictoires, et peinent à maintenir une compréhension fine des réalités métiers. Le data mesh promet donc davantage de proximité, de responsabilisation et de scalabilité organisationnelle. En contrepartie, il exige une culture de gouvernance partagée, des standards explicites, et une plateforme interne suffisamment solide pour éviter l’anarchie.
Dans la réalité, les organisations matures combinent souvent ces modèles. Une même plateforme peut utiliser du batch pour les agrégats de confiance, du streaming pour quelques cas critiques, un socle lakehouse pour la mutualisation technique, et des principes proches du data mesh pour répartir les responsabilités. Le rôle du data engineer n’est pas de défendre un dogme, mais de composer un système cohérent entre besoins métiers, contraintes techniques et capacité réelle d’exploitation.
Le Data Engineering n’est pas un simple empilement d’outils. C’est une chaine de valeur où chaque brique répond à une question précise : comment capter la donnée, comment l’acheminer, comment la transformer, comment la contrôler, comment la documenter, comment l’exposer, et comment la surveiller dans le temps. Ce qui compte n’est donc pas seulement la popularité d’un outil, mais la manière dont il s’insère dans un système exploitable.
L’ingestion couvre plusieurs réalités : extraction via API, chargement de fichiers, synchronisation depuis des SaaS, capture des changements en base transactionnelle (CDC), ingestion d’événements applicatifs, ou flux de logs. Le point critique n’est pas seulement de “récupérer” la donnée, mais de préserver son contexte : horodatage, source, schéma, statut, provenance, et conditions d’arrivée.
Une ingestion mal pensée crée rapidement une dette structurelle : données dupliquées, champs tronqués, pertes silencieuses, historisation absente, et dépendance à des connecteurs opaques. À l’inverse, une ingestion bien conçue prépare la qualité en aval.
L’orchestration permet de piloter l’exécution des pipelines : ordre des tâches, dépendances, reprise après erreur, planification, alertes, logs d’exécution, et visibilité sur l’état global du système. Sans orchestration sérieuse, les pipelines finissent souvent par reposer sur des tâches planifiées isolées, des scripts déclenchés manuellement, ou des dépendances implicites impossibles à maintenir.
Une bonne orchestration ne sert pas uniquement à lancer des jobs. Elle sert aussi à rendre le système lisible : qu’est-ce qui tourne, qu’est-ce qui a échoué, qu’est-ce qui attend, qu’est-ce qui impacte quoi, et quelles équipes doivent intervenir.
Transformer la donnée, ce n’est pas simplement faire des jointures ou renommer des colonnes. C’est traduire un monde opérationnel brut en structures interprétables. À ce niveau apparaissent les notions de tables intermédiaires, de modèles métier, d’agrégats, d’historisation, de gestion des dimensions, et de cohérence sémantique.
Cette couche est stratégique, car c’est là que les erreurs silencieuses deviennent les plus dangereuses : définition ambiguë d’un client actif, statut de commande incohérent selon les systèmes, calcul de revenu différent selon les équipes, ou logique temporelle mal comprise. Une transformation robuste exige donc du versioning, des tests, de la documentation et une gouvernance claire des définitions.
Une plateforme data mature distingue souvent plusieurs zones : une zone brute pour l’atterrissage et la conservation de la source, une zone raffinée pour la normalisation et les enrichissements, puis une zone de consommation pensée pour les usages analytiques ou produits. Cette séparation n’est pas cosmétique. Elle sert à isoler les responsabilités, à améliorer la traçabilité, et à limiter les effets de bord.
Le serving data renvoie à la dernière étape : exposer les données dans un format utile aux consommateurs. Cela peut prendre la forme de tables BI, de vues sémantiques, d’APIs internes, de features pour le ML, ou de corpus préparés pour un moteur RAG.
Les tests qualité ne doivent pas être ajoutés après coup. Ils doivent faire partie de la définition même du pipeline. Parmi les contrôles les plus fréquents : unicité d’un identifiant, non-nullité de champs obligatoires, seuils de volumétrie, conformité à un schéma, cohérence entre tables, validité temporelle, et comparaison avec des historiques de référence.
Il faut également distinguer deux types de défauts : les défauts “bloquants”, qui doivent arrêter un pipeline, et les défauts “surveillés”, qui n’empêchent pas la production mais déclenchent une alerte. Cette distinction est essentielle pour éviter deux excès opposés : produire des données corrompues sans le savoir, ou bloquer tout le système pour des anomalies mineures.
À mesure que la plateforme grandit, l’enjeu n’est plus seulement de produire des données, mais de les rendre trouvables, compréhensibles et auditables. Un catalogue sert à recenser les datasets, leur sens, leur owner, leur niveau de sensibilité et leurs conditions d’usage. Le lineage permet de remonter la chaine de transformation : de quelle source vient un indicateur, quels jobs le construisent, et qui en dépend en aval.
Sans cette couche de visibilité, une plateforme data devient vite un territoire fragmenté : les tables se multiplient, les doublons s’installent, les équipes recréent les mêmes calculs, et la confiance s’érode.
Un bon stack de Data Engineering n’est pas celui qui aligne le plus grand nombre d’outils. C’est celui qui rend les flux compréhensibles, observables, testables, et suffisamment simples pour être exploités durablement.
Les plateformes data les plus fragiles ne sont pas toujours celles qui manquent de technologie. Ce sont souvent celles qui manquent de pratiques d’ingénierie. Le Data Engineering devient réellement mature lorsqu’il adopte des réflexes proches du software engineering : standardisation, revue, testabilité, observabilité, documentation, et culture de l’exploitation.
Un pipeline n’est pas un script isolé. C’est un composant de production. Il doit avoir un owner, un niveau de criticité, des métriques de santé, une stratégie de reprise, une documentation minimale et des conventions de nommage. Sans cela, chaque incident se transforme en enquête, chaque évolution devient risquée, et chaque départ d’un collaborateur laisse un angle mort.
Les contrats de données servent à formaliser ce qui doit rester stable entre producteurs et consommateurs : schéma attendu, types, champs obligatoires, sémantique, fréquence de mise à jour, règles de qualité, comportements en cas d’évolution. Ils ne suppriment pas le changement, mais rendent ce changement gouvernable.
Dans les environnements les plus mouvants, cette logique est décisive. Elle évite que les équipes applicatives modifient un événement ou une table source sans mesurer les conséquences sur l’analytique, le ML ou la facturation.
Un pipeline de qualité n’est pas seulement capable de produire le présent. Il doit pouvoir rejouer le passé. Les backfills et les reprocessings sont inévitables : correction d’un bug, changement de logique métier, arrivée tardive de données, ou migration d’architecture. Si la plateforme n’a pas été conçue pour cela, la moindre correction historique devient coûteuse, lente et risquée.
Les tests utiles en Data Engineering ne se limitent pas à la syntaxe. Ils couvrent plusieurs étages : tests unitaires sur certaines fonctions de transformation, tests de schéma, tests de qualité sur les données produites, tests d’intégration entre composants, et tests de non-régression sur des jeux de données de référence. Le but n’est pas d’atteindre une pureté théorique, mais de réduire le nombre d’erreurs qui atteignent la production.
Une plateforme data moderne doit répondre à trois questions en continu : les données arrivent-elles à temps, ressemblent-elles encore à ce qu’on attend, et combien coûte leur production ? La fraicheur mesure le retard par rapport à l’attendu. La dérive signale des changements de structure ou de distribution. Les coûts rappellent qu’un pipeline “qui marche” peut rester économiquement mal conçu.
Cet angle coût devient crucial avec le cloud. Les requêtes mal partitionnées, les traitements redondants, les scans complets inutiles, les réécritures excessives ou les pipelines déclenchés trop souvent produisent une dette invisible au début, puis difficile à réduire lorsque les usages ont déjà grossi.
Le Data Engineering prend tout son sens lorsqu’on observe ses effets sur des usages réels. Une architecture data n’a pas de valeur en soi. Elle en a parce qu’elle rend possible une lecture plus fiable de l’activité, une meilleure expérience produit, une automatisation plus robuste, ou une exploitation plus crédible de l’IA.
Le cas le plus classique reste la BI. Les équipes finance, direction, marketing ou opérations ont besoin d’indicateurs stables : chiffre d’affaires, marge, acquisition, churn, délai, support, activation, réachat, productivité. Le Data Engineering construit les fondations qui rendent ces métriques auditables. Sans cela, les tableaux de bord deviennent des surfaces visuelles séduisantes mais discutables.
Les équipes produit dépendent d’événements applicatifs bien définis, correctement historisés et reliés à des dimensions stables. Sans instrumentation cohérente, il devient impossible de mesurer un funnel, une rétention, une activation, ou l’impact réel d’une fonctionnalité. Le Data Engineering intervient ici pour normaliser les événements, consolider les identités, corriger les horodatages, et produire des modèles exploitables pour l’analyse.
Dans certains contextes, la valeur de la donnée est liée à la vitesse d’action. C’est le cas du suivi logistique, du monitoring industriel, de la cybersécurité, du pricing dynamique, ou de la détection de comportements suspects. Le Data Engineering ne consiste alors pas seulement à transporter un flux. Il doit garantir que le flux reste interprétable, résilient, et suffisamment propre pour ne pas générer de faux signaux massifs.
Avant même l’entraînement d’un modèle, les données doivent être nettoyées, alignées dans le temps, enrichies, historisées et rendues reproductibles. Cette préparation relève largement du Data Engineering. Une organisation qui veut industrialiser le ML sans socle data fiable rencontre rapidement les mêmes limites : jeux d’entraînement impossibles à reconstruire, features calculées différemment entre entraînement et inférence, documentation lacunaire, ou absence de gouvernance sur les sources utilisées.
Les usages RAG ont redonné une visibilité nouvelle au Data Engineering. Pour qu’un système de recherche augmentée fonctionne correctement, il ne suffit pas d’indexer des documents. Il faut sélectionner les bonnes sources, dédupliquer, versionner, nettoyer, enrichir en métadonnées, gérer les droits d’accès, suivre les mises à jour, et mesurer ce qui a été injecté dans le système. Autrement dit, même dans l’IA générative, la robustesse dépend encore d’un travail d’ingénierie de la donnée.
Quand un projet IA échoue faute de données fiables, le problème est rarement “l’IA” au sens strict. Il se situe très souvent en amont : sources mal gouvernées, pipelines trop fragiles, documentation absente, ou absence de stratégie de qualité.
Le Data Engineering moderne ne peut plus être dissocié de la gouvernance. La croissance des usages analytiques, la circulation accrue des données personnelles ou sensibles, et l’intégration de l’IA imposent un cadre plus rigoureux. La gouvernance ne doit pas être comprise comme une bureaucratie ajoutée après coup, mais comme un ensemble de règles qui rendent la donnée exploitable sans la rendre incontrôlable.
L’accès à la donnée doit être attribué en fonction du besoin réel. Tout le monde n’a pas besoin d’accéder aux mêmes tables, aux mêmes colonnes, ni au même niveau de détail. Cette séparation protège non seulement les informations sensibles, mais aussi la qualité opérationnelle du système : moins de copies sauvages, moins de manipulations hasardeuses, moins de dépendances cachées.
Une plateforme data fiable doit permettre de répondre à des questions simples mais structurantes : d’où vient cette donnée, qui l’a transformée, quand a-t-elle été recalculée, quels changements ont été appliqués, et quels consommateurs dépendent de ce jeu de données ? Sans cette capacité d’audit, la confiance reste superficielle.
Lorsque des données personnelles, contractuelles, financières ou réglementées circulent dans les pipelines, le Data Engineering doit intégrer des mécanismes concrets : classification, masquage, pseudonymisation, journalisation des accès, politiques de rétention, et séparation des environnements. Dans de nombreux contextes, la question n’est pas de savoir si la conformité est nécessaire, mais comment l’intégrer sans dégrader complètement l’usage métier.
Beaucoup d’organisations veulent offrir davantage d’autonomie aux équipes métier ou analytiques. Cette ambition est saine, mais elle ne fonctionne pas sans règles minimales : définition des owners, catalogue, standards de documentation, critères de certification des datasets, conventions de nommage, et politiques d’accès. Le self-service sans gouvernance finit souvent en prolifération de tables concurrentes, de KPI contradictoires et de copies locales incontrôlées.
Le Data Engineering est souvent présenté comme une solution structurante. Il l’est, mais il produit aussi ses propres difficultés. À mesure que les usages augmentent, les pipelines se multiplient, les dépendances s’épaississent, les incidents changent de nature, et la plateforme peut devenir plus complexe qu’elle ne devrait l’être.
La dette de pipeline apparaît lorsqu’un système fonctionne, mais au prix de compromis accumulés : duplication de traitements, conventions implicites, absence de tests, tables intermédiaires sans owner, nomenclature instable, patchs ajoutés en urgence, et transformations devenues incompréhensibles. Cette dette est dangereuse parce qu’elle n’empêche pas immédiatement la production. Elle la fragilise progressivement.
Un autre risque est l’empilement technologique. Sous prétexte de modernité, certaines équipes accumulent de nombreux composants spécialisés avant même d’avoir stabilisé leurs besoins. Le résultat est paradoxal : plus d’outils, mais moins de lisibilité. Plus de sophistication, mais moins de résilience. La maturité ne se mesure pas au nombre de logos présents dans l’architecture.
Le Data Engineering se situe à l’intersection du logiciel, de la donnée, du cloud, de la sécurité, de l’exploitation et du métier. Cette hybridation rend le rôle exigeant. Les profils doivent savoir coder, modéliser, comprendre l’infrastructure, raisonner en production, et dialoguer avec plusieurs équipes. Il n’est donc pas surprenant que les organisations rencontrent des tensions de recrutement ou de structuration.
Dans beaucoup d’entreprises, les principaux blocages ne sont pas purement techniques. Ils concernent l’ownership des données, la stabilité des définitions, la priorité donnée à la dette par rapport aux nouvelles demandes, ou les tensions entre centralisation et autonomie. Une plateforme data peut être bien conçue techniquement tout en restant inefficace si ces arbitrages ne sont jamais clarifiés.
Le Data Engineering ne supprime pas la complexité du réel. Il la rend visible, pilotable et partiellement maîtrisable. C’est déjà beaucoup, mais cela suppose d’accepter qu’aucune architecture n’élimine entièrement les conflits d’usage, les contraintes de coûts ou les compromis organisationnels.
Les tendances récentes montrent un déplacement du centre de gravité. L’enjeu n’est plus seulement de déplacer ou de stocker les données. Il devient de plus en plus question d’interopérabilité, de lisibilité, de gouvernance active et d’intégration avec les usages IA.
Les formats de table ouverts gagnent en importance parce qu’ils structurent l’interopérabilité entre moteurs, la gestion transactionnelle, le versioning, et l’évolution des architectures lakehouse. Ils deviennent un sujet d’architecture à part entière, et non plus un simple détail de stockage.
Le catalogue n’est plus seulement un annuaire. Il devient une interface de gouvernance, de découverte, de certification et d’audit. Dans les environnements riches en jeux de données, il contribue directement à la réduction des doublons et à la restauration de la confiance.
Les équipes ne se contentent plus de vérifier qu’un job a “réussi”. Elles cherchent à savoir si les données produites sont plausibles, fraîches, cohérentes, complètes et économiquement soutenables. Cette montée de l’observabilité rapproche le Data Engineering d’une logique SRE appliquée à la donnée.
Avec la montée des systèmes IA fondés sur des documents, des logs, des bases de connaissances et des données non structurées, les pipelines de préparation, de nettoyage, d’indexation et de contrôle d’accès deviennent plus visibles. Les organisations découvrent qu’un corpus mal gouverné produit une IA mal gouvernée.
Les approches dites “agentiques” ou semi-autonomes attirent l’attention, mais elles reposent elles aussi sur des fondations data sérieuses. Des agents qui lisent des données erronées, mal documentées ou non autorisées n’automatisent pas le travail : ils industrialisent l’erreur. Derrière la promesse d’autonomie, les besoins de traçabilité, de contrôle d’accès et de qualité augmentent.
Non. La Data Science se concentre davantage sur l’analyse, la modélisation statistique et l’apprentissage automatique. Le Data Engineering construit et opère l’infrastructure logique et technique qui rend les données fiables, disponibles et exploitables.
Le data engineer travaille plus souvent sur l’ingestion, les pipelines, le stockage, l’orchestration et la fiabilité globale. L’analytics engineer se concentre davantage sur la modélisation analytique, les règles métier, la documentation sémantique et la mise à disposition de modèles fiables pour la BI et l’analyse.
Non. Le temps réel n’est pertinent que si le métier en retire une valeur mesurable. Dans beaucoup de cas, des traitements batch bien conçus suffisent largement et offrent un meilleur rapport entre simplicité, coût et robustesse.
Oui. Les systèmes RAG, les pipelines documentaires, la gestion des métadonnées, la gouvernance des corpus, la fraicheur des sources et le contrôle des accès relèvent très directement d’un travail d’ingénierie de la donnée.
Oui, à condition de viser la sobriété. Une petite équipe peut construire un socle très solide si elle privilégie les conventions, les tests, la documentation et une architecture lisible, plutôt qu’un empilement prématuré d’outils complexes.
Le Data Engineering n’est plus un rôle périphérique chargé de déplacer des données entre quelques systèmes. Il constitue désormais une fonction structurante de l’entreprise numérique. Il rend possible un pilotage plus fiable, une meilleure lecture des usages produit, une gouvernance plus crédible, et une exploitation plus sérieuse de l’IA.
Son importance vient d’un fait simple : aucune organisation ne peut durablement appuyer ses décisions, ses produits ou ses modèles sur des données dont elle ne comprend ni l’origine, ni la qualité, ni les conditions de mise à jour. Derrière chaque indicateur robuste, chaque pipeline ML reproductible, chaque système RAG fiable, on retrouve les mêmes exigences : instrumentation, transformation maîtrisée, documentation, contrôle d’accès, observabilité, et capacité à rejouer l’histoire quand le réel contredit les hypothèses initiales.
Le Data Engineering ne promet pas un monde sans complexité. Il propose quelque chose de plus réaliste : transformer une matière première instable en un système exploitable, gouverné et évolutif. C’est précisément cette capacité qui en fait aujourd’hui l’un des socles les plus stratégiques de la chaîne de valeur data.