Lambda ou Kappa ? Le choix de l’architecture de streaming détermine la complexité, la latence et la maintenabilité de vos pipelines. Comparatif complet des deux modèles.
Résumé
L’architecture Lambda (batch + speed) a dominé la première génération du streaming. L’architecture Kappa (streaming unifié) propose une alternative plus simple quand les contraintes de traitement en temps réel le permettent. Ce guide compare les deux modèles : leur fonctionnement, leurs avantages (Lambda : exactitude, tolérance aux pannes ; Kappa : simplicité de code, unique moteur), leurs inconvénients (Lambda : double logique ; Kappa : reprocessing coûteux), et leurs domaines de prédilection. Des schémas, des exemples d’implémentation (Kafka, Spark, Flink) et un arbre de décision aident à choisir l’architecture adaptée à vos besoins de latence, de volume et de maintenance.
Table des matières
1. Contexte : pourquoi deux architectures pour le streaming ?
Le traitement des données en temps réel a longtemps souffert d’une tension : les moteurs batch (Hadoop, Spark batch) sont précis, robustes, mais lents (plusieurs minutes/heures). Les moteurs streaming (Storm, premières versions de Spark Streaming) sont rapides (quelques secondes), mais moins tolérants aux pannes et moins exacts (au moins une fois).
L’architecture Lambda (2011) a proposé un compromis : faire les deux. L’architecture Kappa (2014) a osé : et si on ne faisait que du streaming, avec assez de rétention pour recalculer ?
2. Architecture Lambda : le compromis batch + speed
Lambda segmente le pipeline en trois couches :
- Batch layer : stocke l’intégralité des données brutes (HDFS, S3). Lance périodiquement des jobs batch (Spark, Hive) pour précalculer des vues (résultats exacts sur tout l’historique).
- Speed layer : traite les données récentes en streaming (Storm, Flink, Kafka Streams, Spark Streaming) pour compenser la latence du batch. Ces résultats sont approximatifs ou incomplets.
- Serving layer : fusionne les résultats des deux couches à la requête, renvoyant soit la vue batch (quand disponible), soit la vue speed, soit une combinaison.
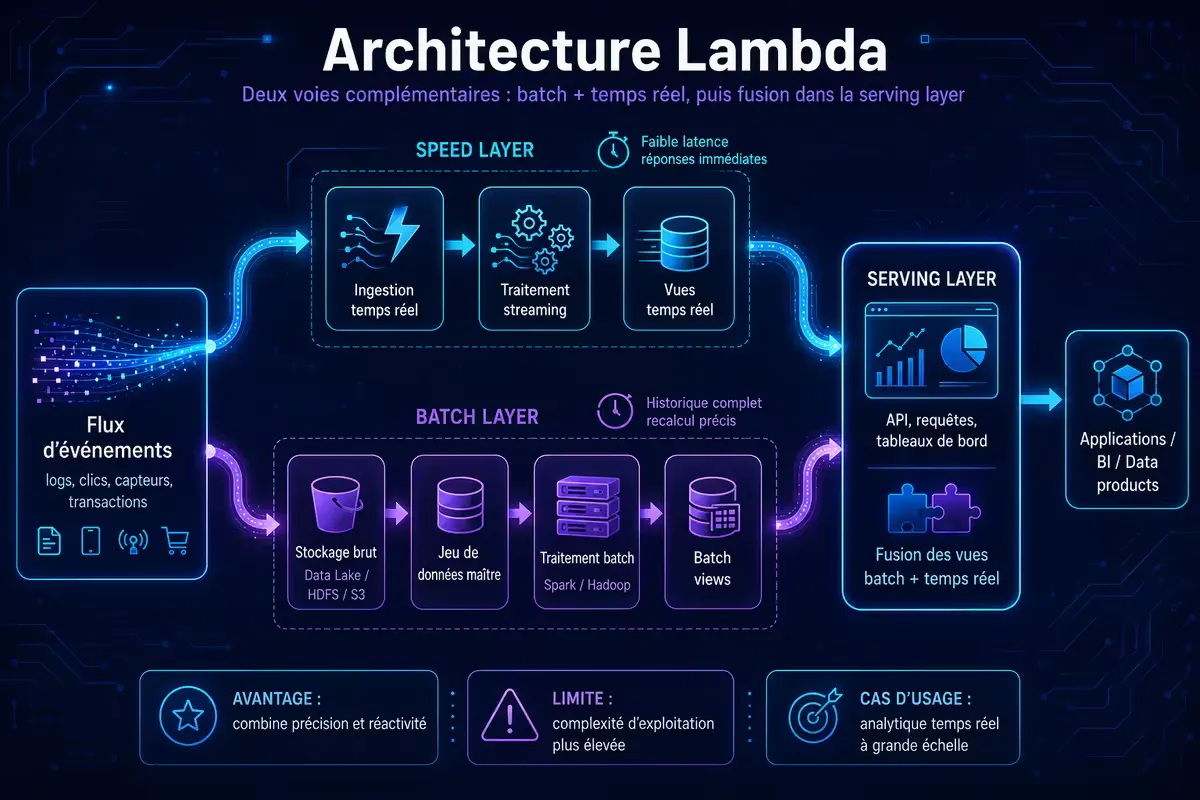
Figure 1 — Architecture Lambda : deux voies de traitement parallèles (batch et speed) fusionnées à la lecture.
✅ Avantages de Lambda
- Robustesse : le batch garantit l’exactitude sur l’historique complet.
- Latence maîtrisée : le speed assure des réponses rapides sur les données récentes.
- Tolérance aux pannes : si le speed échoue, on peut attendre le prochain batch.
❌ Inconvénients de Lambda
- Double code : la même logique métier doit être implémentée deux fois (batch et speed). Risque d’incohérence.
- Complexité opérationnelle : deux pipelines, deux SLA, deux jeux de monitoring.
- Décalage possible : les résultats entre batch et speed peuvent diverger (notamment dans les fenêtres glissantes).
3. Architecture Kappa : le streaming unifié
Kappa simplifie : tout est stream. Une seule couche de traitement lit le flux d’événements depuis une file (Kafka, Pulsar). Pour recalculer un résultat (nouvelle logique, correction d’erreur), on rejoue le flux depuis un offset antérieur.
- Message bus central : Kafka (ou Pulsar, Redpanda) avec rétention longue (jours, mois).
- Processing engine : Kafka Streams, Flink, Spark Structured Streaming, ou toute bibliothèque stream native.
- Sink : base de données de service (Elasticsearch, Cassandra, Druid, ClickHouse) pour les résultats.
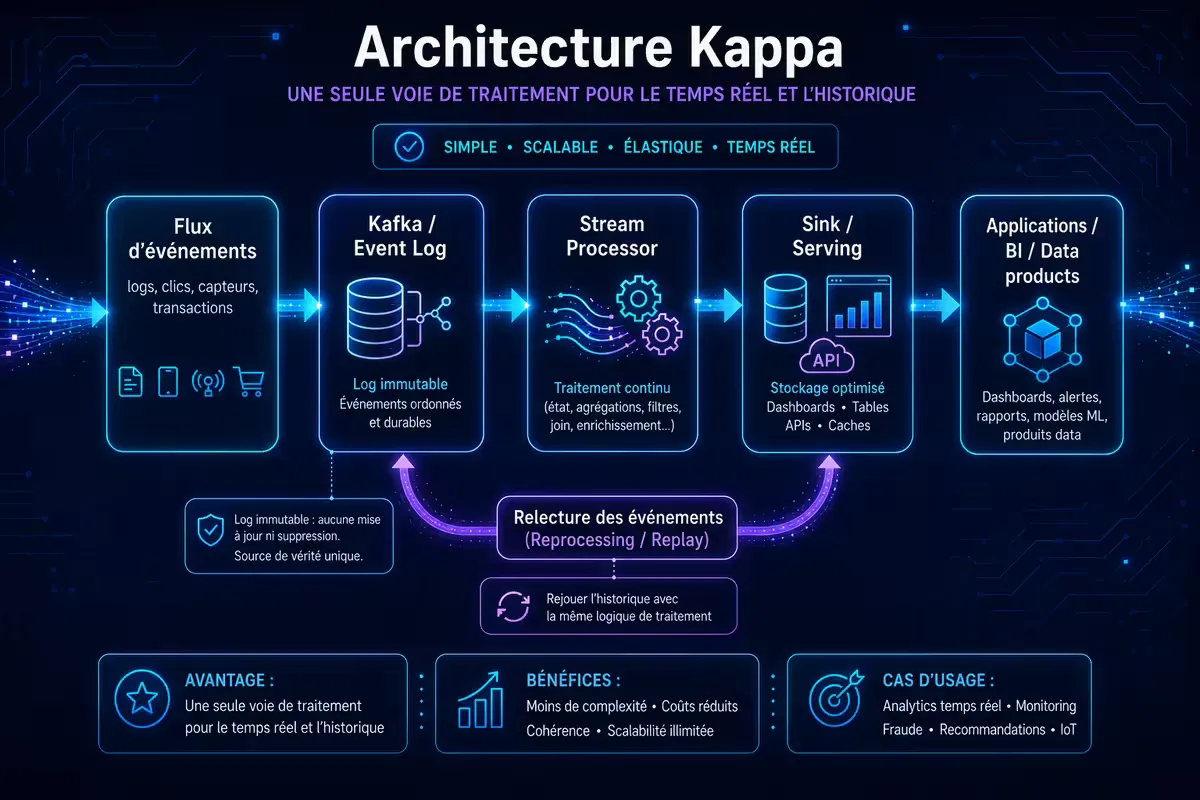
Figure 2 — Architecture Kappa : une seule voie de traitement streaming ; le recalcul se fait par rejeu depuis Kafka.
✅ Avantages de Kappa
- Code unique : une seule logique métier, plus simple à maintenir.
- Pas de fusion : pas de risque d’incohérence entre batch et speed.
- Reprocessing à la demande : correction possible a posteriori.
❌ Inconvénients de Kappa
- Coût du reprocessing : pour recalculer sur des mois de données, il faut le temps et les ressources.
- Rétention longue : conserver des téraoctets dans Kafka peut être cher (mais des solutions comme tiered storage atténuent).
- Exactitude dépend du moteur : tous les moteurs streaming ne garantissent pas la sémantique exactly‑once (mais Flink, Kafka Streams et Spark Structured Streaming le font bien).
4. Comparatif Lambda vs Kappa

Figure 3 — Synthèse des différences Lambda / Kappa.
| Critère | Architecture Lambda | Architecture Kappa |
|---|---|---|
| Nombre de pipelines | 2 (batch + speed) | 1 (stream) |
| Logique métier | Dupliquée (deux implémentations) | Unifiée (une seule version) |
| Latence type | Secondes (speed) à heures (batch) | Secondes / millisecondes (stream) |
| Exactitude sur historique | Parfaite (batch recompute) | Dépend du reprocessing (mais théoriquement identique) |
| Reprocessing (changement de logique) | Rejouer le batch (coûteux, mais fait périodiquement) | Rejouer le stream depuis Kafka (coût potentiel, mais occasionnel) |
| Complexité opérationnelle | Élevée (deux pipelines, fusion) | Modérée (un pipeline, pas de fusion) |
| Cas typique | Mélange de traitements historiques lourds + temps réel (recommandation, IoT) | Streaming pur avec besoin de recalcul occasionnel (logs, clics, métriques produit) |
5. Quand choisir Lambda ? Quand choisir Kappa ?
Choisir Lambda si…
- Vous avez déjà un lourd patrimoine batch (Hive, Spark batch) et ne pouvez pas le remplacer.
- Les calculs batch sont très complexes, et les réécrire en streaming serait un effort disproportionné.
- Vos volumes sont si énormes que le streaming ne peut pas traiter l’intégralité de l’historique (mais les progrès de Flink/Spark atténuent ce point).
- Vous travaillez dans un secteur très régulé où l’exactitude absolue sur tout l’historique est une obligation (finance, assurance).
Choisir Kappa si…
- Vous commencez un nouveau projet de streaming.
- Vous pouvez conserver les événements bruts longtemps (Kafka tiered storage).
- Vous acceptez que le reprocessing occasionnel prenne du temps (il n’est pas fait à chaque requête).
- Vous voulez minimiser la dette technique (code unique).
- Votre besoin de latence est homogène (pas de distinction nette entre « historique batch » et « récent speed »).
Règle moderne (2026) : par défaut, Kappa est le bon choix. La plupart des moteurs stream (Flink, Spark Structured Streaming, Kafka Streams) sont matures, exactly‑once, et capables de traiter des volumes historiques via le reprocessing. Lambda est réservé aux cas où des contraintes fortes imposent de garder le batch.
6. Mise en œuvre : exemples concrets
Lambda-type avec Spark
- Batch : Spark SQL quotidien sur les données en S3/Delta Lake.
- Speed : Spark Structured Streaming (micro‑batch) sur Kafka pour les dernières minutes.
- Serving : base de données (Druid, ClickHouse) qui interroge les deux ensembles.
Kappa-type avec Kafka + Flink
- Source : événements dans Kafka (rétention 30 jours).
- Traitement : Flink job unique qui applique la fenestration, agrégations, jointures.
- Sink : résultats dans Elasticsearch ou CockroachDB.
- Reprocessing : pour modifier la logique, on lance un nouveau Flink job à partir d’un offset Kafka antérieur.
DataStream<Event> stream = env
.addSource(new FlinkKafkaConsumer<>("topic", schema, props))
.keyBy(Event::getUserId)
.window(SlidingProcessingTimeWindows.of(Time.minutes(5), Time.minutes(1)))
.aggregate(new CountAggregate());
stream.addSink(new ElasticsearchSink<>());7. Tendances 2026 : vers la convergence ?
- Streaming-first avec batch opportuniste : Spark Structured Streaming et Flink peuvent exécuter des requêtes batch sur des données historiques en utilisant le même moteur. La distinction s’estompe.
- Tiered storage dans Kafka (Kafka 3.5+, 2024) : stocker les anciennes données sur S3/HDFS rend la rétention longue abordable.
- Matérialized views sur streams : des bases comme RisingWave ou Materialize transforment des flux en vues actualisées en continu, mélangeant idéalement stream et batch.
- Déclin de Lambda : les nouveaux projets en 2026 adoptent massivement Kappa, sauf contrainte particulière.
À retenir : L’architecture Kappa est devenue la référence par défaut pour les pipelines streaming. Lambda reste un motif de repli pour les systèmes hérités ou les exigences extrêmes de double validation.
Revenir au guide complet
Cet article fait partie du guide complet sur le Big Data qui couvre les architectures modernes de données.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
FAQ
Qu’est-ce que l’architecture Lambda ?
Proposée par Nathan Marz (2011), Lambda segmente le traitement en deux couches : une couche batch (traitement de lots sur l’historique complet, précision maximale) et une couche speed (traitement temps réel sur les données récentes, latence faible). Les résultats des deux couches sont fusionnés à la lecture. L’avantage : la robustesse et l’exactitude du batch couplées à la rapidité du streaming. L’inconvénient : la double logique métier à maintenir.
Qu’est-ce que l’architecture Kappa ?
Proposée par Jay Kreps (2014, co-créateur d’Apache Kafka), Kappa simplifie Lambda en supprimant la couche batch. Toutes les données sont traitées comme un flux continu (streaming). Si un recalcul est nécessaire, on rejoue le flux depuis un point antérieur (reprocessing). L’avantage : un seul code à maintenir. L’inconvénient : le reprocessing peut être lourd et nécessite une rétention longue des événements.
Quand utiliser Lambda plutôt que Kappa ?
Lambda reste pertinent quand : (1) les calculs batch sont très complexes et coûteux à répliquer en streaming, (2) vous avez besoin de deux pipelines distincts pour des raisons de maintenabilité, (3) vos outils historiques sont orientés batch et ne peuvent pas être remplacés. Pour les nouveaux projets, Kappa est généralement préférée.
Quels sont les outils typiques pour Lambda et Kappa ?
Lambda : batch (Spark, Flink batch, Hive) + speed (Spark Streaming, Flink, Kafka Streams, Storm) + stockage (HDFS, S3, Delta Lake) + serveur de fusion (Druid, ClickHouse). Kappa : Kafka comme bus central événementiel, traitement par Kafka Streams, Flink, ou Spark Structured Streaming, et base de données de service (Elasticsearch, Cassandra, Pinot).
Kappa gère-t-elle les données historiques et les recalculs ?
Oui, à condition de conserver les événements bruts longtemps (par exemple, rétention Kafka de plusieurs mois ou années). Pour recalculer un résultat, on lance un nouveau job stream qui lit depuis un offset antérieur. Cette opération peut être coûteuse, mais n’arrive qu’occasionnellement.
Peut-on faire du machine learning avec Kappa ?
Oui. On peut entraîner des modèles en batch séparément (en lisant depuis Kafka), puis déployer l’inférence en streaming via Kafka Streams, Flink, ou une librairie dédiée. La couche d’entraînement n’a pas besoin d’être en streaming. Kappa ne supprime pas le batch, elle unifie la logique de traitement.
Sources
- Marz, N. (2011) – Lambda Architecture (blog)
- Kreps, J. (2014) – Questioning the Lambda Architecture (Confluent blog)
- Apache Kafka documentation – Tiered storage
- Apache Flink – Streaming Analytics
- Spark Structured Streaming – Unified batch + streaming
- Wikipédia – Lambda architecture
Article mis à jour le 28 mai 2026.