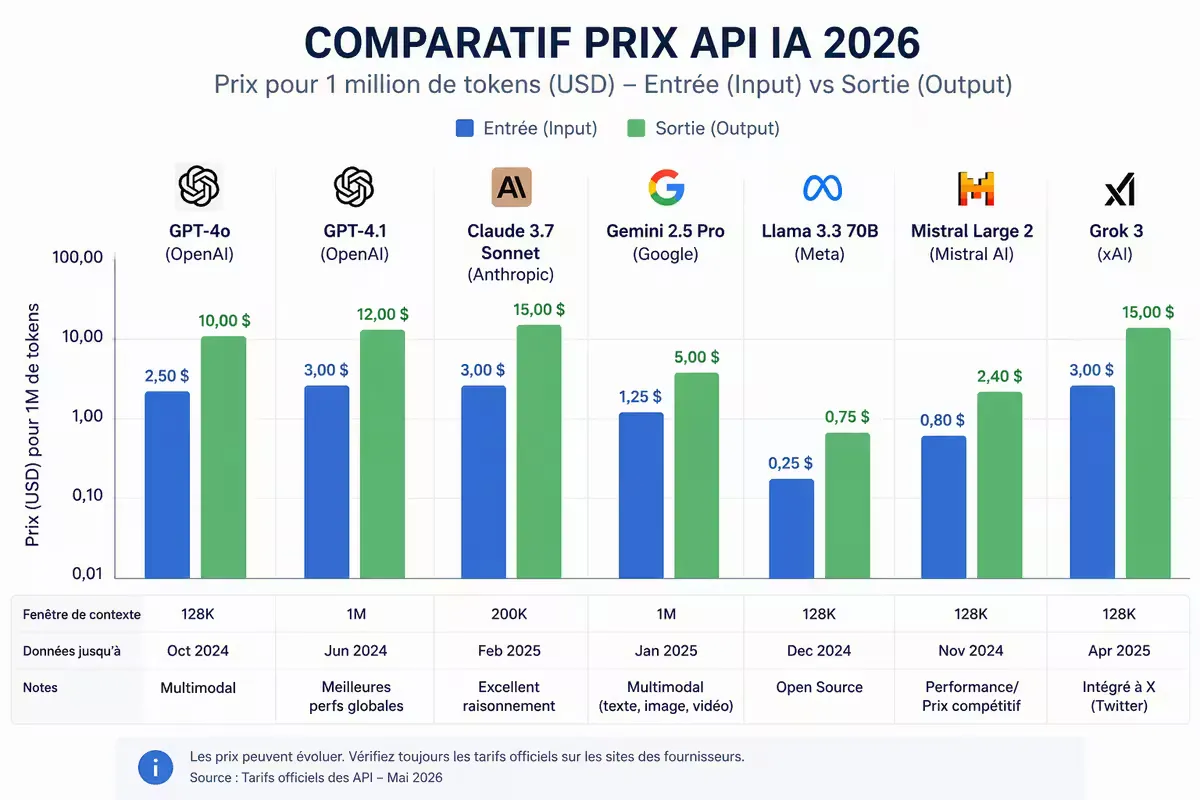
Image principale : graphique à barres comparant les prix entrée/sortie des modèles principaux .
Quel LLM API offre le meilleur rapport qualité-prix en 2026 ? Comparatif des tarifs, coûts cachés et simulateurs pour GPT-5, Gemini, Claude, Llama, Mistral.
Résumé
Le choix d’un modèle de langage via API ne dépend pas seulement des performances : le coût à l’usage est crucial. Ce comparatif détaille les tarifs officiels (entrée/sortie) des principaux fournisseurs : OpenAI (GPT-5, GPT-4o), Google (Gemini 2.5 Pro/Flash), Anthropic (Claude 4), et les hébergeurs open source (Together.ai, Groq pour Llama 3, Mistral). Nous analysons les coûts cachés (contexte long, fine‑tuning, batch), proposons des exemples concrets de calcul, et aidons à choisir selon votre volume et vos besoins.
Table des matières
1. Pourquoi ce comparatif est indispensable
En 2026, le marché des API LLM est mature, mais les grilles tarifaires restent complexes. Les différences de prix entre fournisseurs peuvent atteindre un facteur 10, et des options comme le contexte long ou le fine‑tuning modifient profondément la facture. Ce guide vous aide à anticiper vos coûts et à choisir le modèle le plus économique pour votre cas d’usage.
2. Tarifs officiels par fournisseur (par million de tokens)
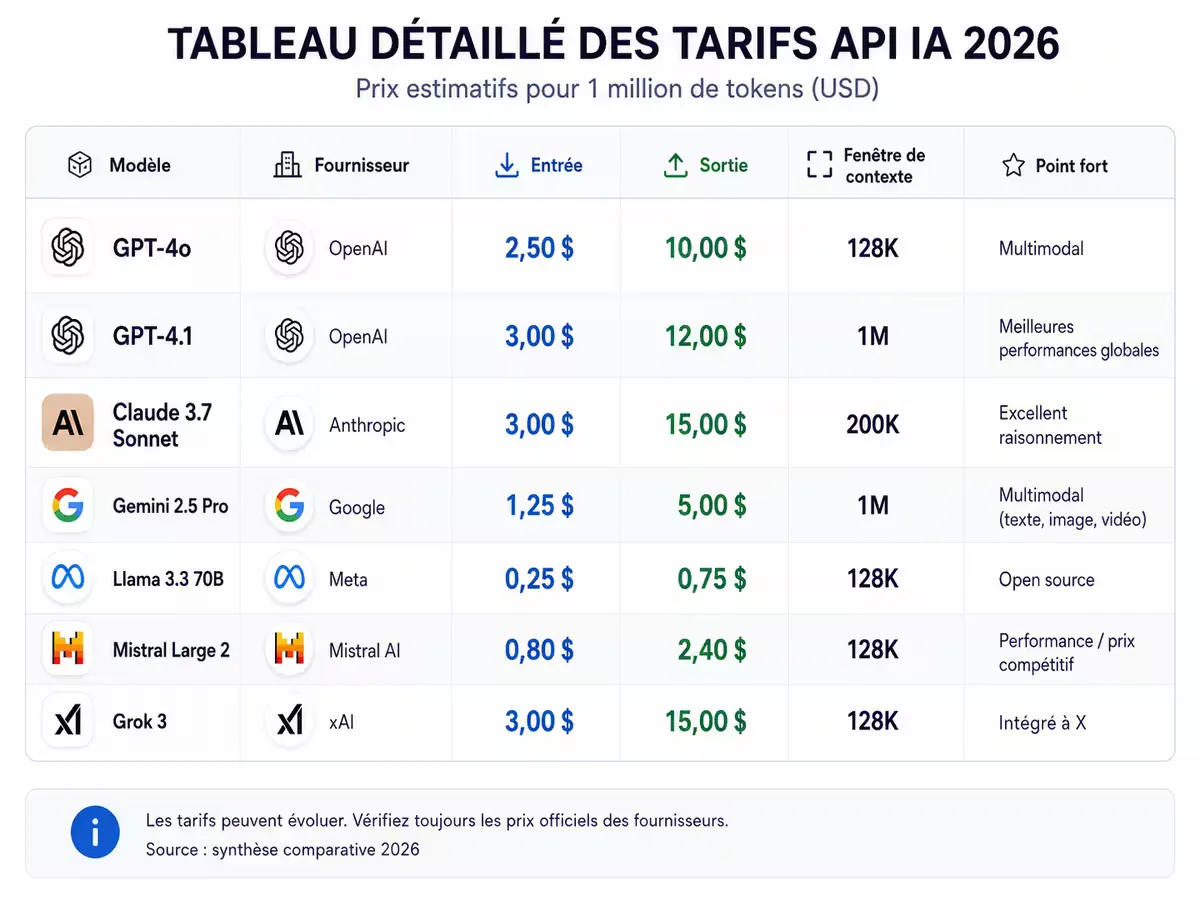
Figure 1 — Comparatif des prix par million de tokens (entrée / sortie) au 22 mai 2026.
OpenAI
| Modèle | Entrée ($/M tokens) | Sortie ($/M tokens) |
|---|---|---|
| GPT-5 | 1,25 | 10,00 |
| GPT-5.2 | 1,50 | 12,00 |
| GPT-5.3 Codex | 1,25 | 10,00 |
| GPT-4o | 0,50 | 1,50 |
| GPT-4o-mini | 0,15 | 0,60 |
| text-embedding-3-large | 0,13 | – |
Google (Vertex AI / Gemini)
| Modèle | Entrée ($/M tokens) | Sortie ($/M tokens) |
|---|---|---|
| Gemini 2.5 Pro (≤200k ctx) | 1,25 | 10,00 |
| Gemini 2.5 Pro (>200k ctx) | 2,50 | 15,00 |
| Gemini 2.5 Flash | 0,35 | 0,70 |
| Gemini 2.0 Flash | 0,10 | 0,40 |
Anthropic
| Modèle | Entrée ($/M tokens) | Sortie ($/M tokens) |
|---|---|---|
| Claude 4 | 1,50 | 7,50 |
| Claude 3.5 Sonnet | 3,00 | 15,00 |
Open source via hébergeurs (Together.ai, Groq, Fireworks)
| Modèle | Entrée ($/M tokens) | Sortie ($/M tokens) |
|---|---|---|
| Llama 3 (70B) | 0,90 | 0,90 |
| Llama 3 (8B) | 0,20 | 0,20 |
| Mistral Large 2 (123B) | 1,00 | 1,00 |
| Mixtral 8x22B | 0,65 | 0,65 |
| Qwen 2.5 (72B) | 0,95 | 0,95 |
Remarque : Les modèles open source sont souvent facturés au même prix entrée/sortie. Les hébergeurs peuvent appliquer des frais supplémentaires pour les appels longs ou la priorité haute.
3. Coûts cachés et spécificités à surveiller
Contexte long (Gemini 2.5 Pro)
Google double le prix entrée et +50 % sortie au‑delà de 200 000 tokens. Si vous utilisez régulièrement de très longs contextes, le coût peut exploser. Privilégiez alors GPT-5 (400k tokens sans surcoût) ou Llama 3 via hébergeur.
Fine‑tuning
- OpenAI : entraînement à 0,10 $/1k tokens (GPT-5). Inférence au même prix que le modèle de base.
- Google : fine‑tuning Gemini 1.5 Pro à 0,25 $/1k tokens d’entraînement, inférence +20 %.
- Open source : vous payez le coût de calcul (ex: 2 $/heure sur GPU spot), pas de surcoût à l’inférence.
Batch processing
OpenAI propose une réduction de 50 % pour les requêtes batch (soumission par lots, délai jusqu’à 24h). Utile pour les traitements massifs non urgents.
Appels d’outils (search, code interpreter)
Google facture la recherche web intégrée en supplément (environ 0,10 $ par appel). Anthropic et OpenAI incluent certains outils dans le prix standard.
3. Simulation de coût pour cas d’usage type
Prenons un chatbot interne d’entreprise avec 10 000 requêtes par jour, moyenne de 500 tokens entrée et 800 tokens sortie par requête.
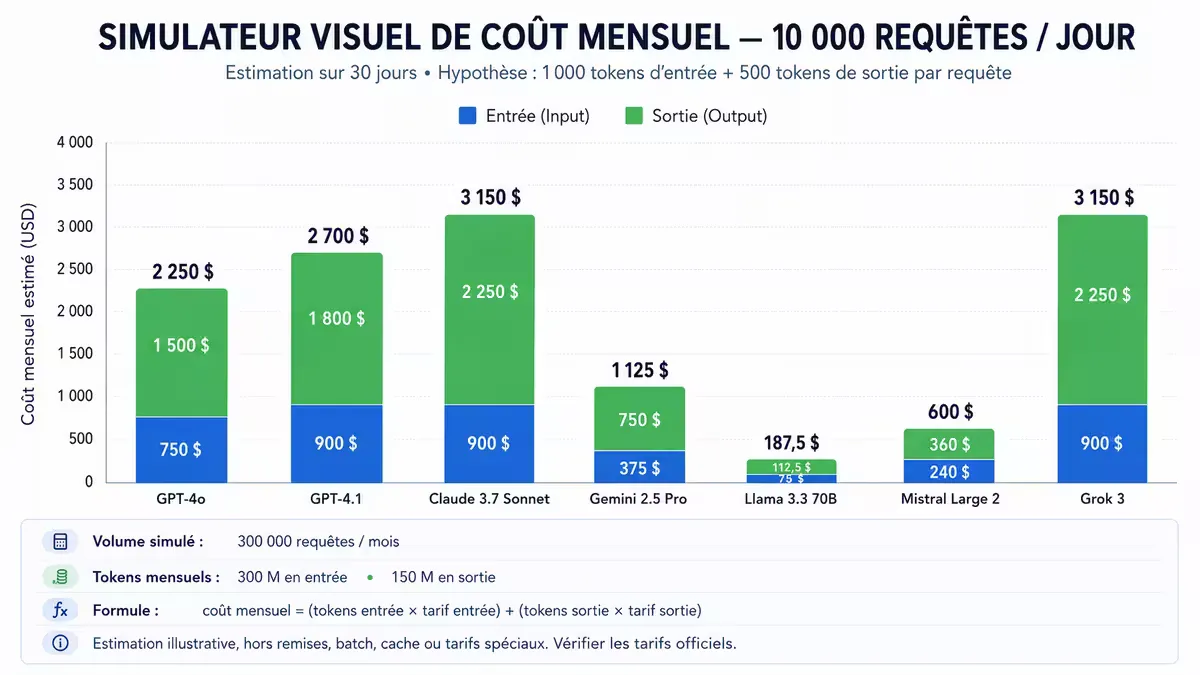
Figure 2 — Coût mensuel estimé pour 300 000 requêtes (10k/jour sur 30 jours).
Calculs (coût mensuel)
| Modèle | Coût entrée (300k req × 500 tokens × prix) | Coût sortie (300k × 800 tokens × prix) | Total mensuel |
|---|---|---|---|
| GPT-5 | 300k × 500 × (1,25/M) = 187,50 $ | 300k × 800 × (10/M) = 2 400 $ | 2 587,50 $ |
| GPT-4o | 300k × 500 × (0,50/M) = 75 $ | 300k × 800 × (1,50/M) = 360 $ | 435 $ |
| Gemini 2.5 Pro | 187,50 $ | 2 400 $ | 2 587,50 $ |
| Gemini 2.5 Flash | 300k × 500 × (0,35/M) = 52,50 $ | 300k × 800 × (0,70/M) = 168 $ | 220,50 $ |
| Claude 4 | 300k × 500 × (1,50/M) = 225 $ | 300k × 800 × (7,50/M) = 1 800 $ | 2 025 $ |
| Llama 3 70B (Together) | 300k × 500 × (0,90/M) = 135 $ | 300k × 800 × (0,90/M) = 216 $ | 351 $ |
Enseignements
- Pour un usage intensif, privilégiez Gemini 2.5 Flash (très économique) ou Llama 3 70B si vous acceptez une légère baisse de qualité.
- GPT-5 et Gemini 2.5 Pro sont très chers sur la sortie, réservés aux tâches critiques nécessitant leur niveau de raisonnement.
- GPT-4o reste un excellent compromis qualité/prix.
5. Quel modèle choisir selon votre volume ?
| Volume mensuel (requêtes) | Budget mensuel | Modèles recommandés |
|---|---|---|
| < 10 000 | < 50 $ | GPT-4o-mini, Gemini 2.0 Flash, Llama 3 8B |
| 10 000 – 100 000 | 50 – 500 $ | GPT-4o, Gemini 2.5 Flash, Llama 3 70B |
| 100 000 – 1 M | 500 – 5 000 $ | Batch GPT-4o, Llama 3 70B (volume négocié) |
| > 1 M | > 5 000 $ | Contacter les fournisseurs pour tarifs personnalisés |
Astuce économie : Si votre application supporte un délai de réponse de quelques minutes, utilisez le batch processing (OpenAI) ou des instances spot/on‑demand pour modèles open source. Réduction jusqu’à 70 %.
6. Tendances des prix 2024-2026
Les prix des API LLM ont chuté de 60 % à 80 % depuis 2024, sous l’effet de la concurrence et de l’optimisation matérielle. En 2026, la baisse ralentit, mais quelques évolutions :
- Les modèles mini (GPT-4o-mini, Gemini 2.0 Flash) ont démocratisé l’IA à très bas coût.
- Les open source hébergés s’alignent sur des prix compétitifs (0,90 $/M tokens pour Llama 3 70B).
- Les modèles de raisonnement (GPT-5, Gemini 2.5 Pro) restent chers car ils nécessitent beaucoup de calcul.
Prévision 2027 : stabilisation des prix, avec peut-être une nouvelle baisse des modèles de raisonnement lorsque les puces dédiées (TPU v7, NVIDIA Blackwell) seront massivement déployées.
Revenir au comparatif principal
Pour confronter ces prix aux performances réelles, consultez notre comparatif GPT-5 vs Gemini 2.5 Pro.
Articles connexes
FAQ
Quel est le LLM API le moins cher en 2026 ?
Pour les modèles open source hébergés (Together.ai, Groq), Llama 3 70B coûte environ 0,90 $/M tokens entrée et sortie. Mais si vous cherchez un modèle propriétaire, Gemini 2.5 Flash (0,35 $/0,70 $) et GPT-4o-mini (0,15 $/0,60 $) sont les moins chers. Pour les gros volumes, contacter directement les fournisseurs pour des tarifs négociés.
Pourquoi le prix à la sortie (completion) est-il plus élevé que l’entrée ?
Générer des tokens (sortie) nécessite plus de calcul que l’encodage de l’entrée, car le modèle doit produire séquentiellement chaque token (pas de parallélisation). Les coûts de calcul et de mémoire sont donc plus élevés, répercutés dans la tarification.
Y a‑t‑il des coûts cachés dans les API LLM ?
Oui : le contexte long (certains quadruplent le prix au‑delà d’un seuil), le fine‑tuning (coût d’entraînement + inférence du modèle fine‑tuné souvent facturée plus cher), le batch processing (parfois un surcoût), et les appels à des outils externes (recherche web, exécution de code). Lisez les grilles détaillées avant de vous engager.
Comment estimer ma facture mensuelle ?
Utilisez la formule : (tokens entrée × prix entrée/M) + (tokens sortie × prix sortie/M). Un outil simple : simulez avec un volume typique (ex: 10 000 appels, 500 tokens entrée, 800 tokens sortie) et comparez les fournisseurs. Nos tableaux ci‑dessous vous aident.
Les modèles open source via API sont-ils vraiment moins chers ?
Oui, mais avec des compromis : latence parfois plus élevée, moins de garanties de disponibilité, options de support limitées. Pour un usage de production critique, les API propriétaires (OpenAI, Google, Anthropic) offrent des SLA plus solides. Le choix dépend de votre tolérance au risque.
Le fine‑tuning augmente‑t‑il le coût d’inférence ?
Chez OpenAI, un modèle fine‑tuné est facturé au même prix que le modèle de base. Chez d’autres fournisseurs, il peut y avoir un surcoût (ex: +20 %). L’entraînement lui‑même est facturé en sus (environ 0,10 $ à 0,50 $ par 1 000 tokens d’entraînement).
Sources
- OpenAI – Pricing page (mai 2026)
- Google – Gemini API pricing (mai 2026)
- Anthropic – Claude 4 pricing (mai 2026)
- Together.ai – Models pricing (mai 2026)
- Groq – Cloud pricing (mai 2026)
- Fireworks AI – Model pricing (mai 2026)
Article mis à jour le 22 mai 2026. Les prix sont donnés à titre indicatif et peuvent changer sans préavis.