
Figure principale — Les feature engineering sont de véritables blocs de construction du ML.
Le feature engineering est souvent ce qui distingue un bon modèle d’un grand modèle. Guide complet des techniques pour créer les variables qui font la différence.
Résumé
Le feature engineering (création de variables) est l’étape du machine learning où la connaissance métier rencontre les techniques de transformation de données. Bien fait, il permet d’obtenir des modèles plus performants avec moins de données. Ce guide présente les méthodes fondamentales : transformations numériques (log, puissance, Box-Cox), encodage de variables catégorielles (one-hot, target encoding, frequency encoding), création de features d’interaction, extraction de dates, binning, variables polynomiales, et aggrégations par groupe. Des exemples concrets en Python (pandas, scikit-learn, feature-engine) illustrent chaque technique. Enfin, les bonnes pratiques pour éviter le data leakage et organiser le code (pipelines) sont détaillées.
Table des matières
- Qu’est-ce que le feature engineering et pourquoi est-il crucial ?
- Transformations numériques
- Encodage des variables catégorielles
- Création de features d’interaction et polynomiales
- Extraction à partir des dates et textes
- Binning et discrétisation
- Features d’agrégation et statistiques par groupe
- Automatisation et pipelines
- Bonnes pratiques et pièges
- FAQ
1. Qu’est-ce que le feature engineering et pourquoi est-il crucial ?
Le feature engineering est l’art de transformer les données brutes en variables (features) qui « parlent » mieux à l’algorithme. Là où un modèle linéaire ne verra qu’une colonne date, un bon feature engineer en extraira jour_de_semaine, est_weekend, mois, depuis_fin_annee.
Pourquoi est-ce si important ?
- Des données mieux structurées réduisent le besoin en données : un bon feature engineering peut faire mieux qu’un doublement du jeu d’entraînement.
- Il intègre la connaissance métier : c’est le seul endroit où l’expertise humaine se traduit directement en amélioration du modèle.
- Il peut transformer un modèle linéaire faible en modèle compétitif (via des interactions et transformations).
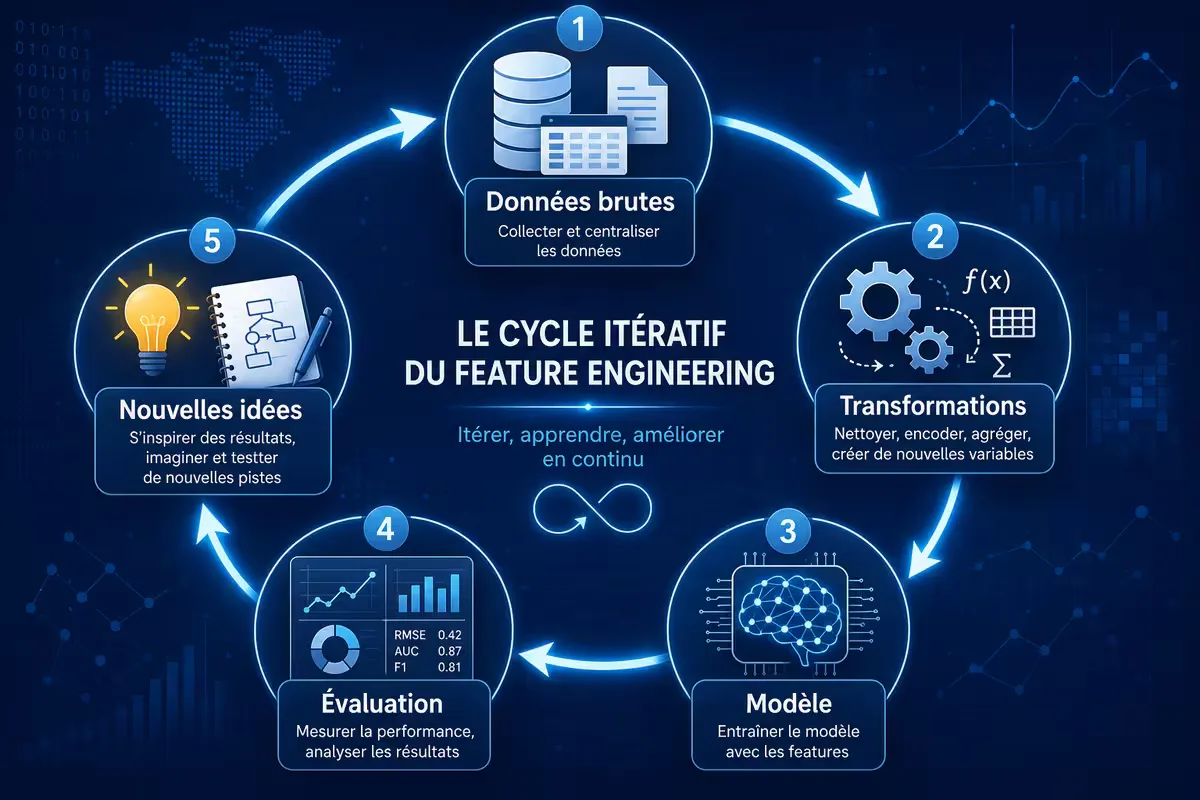
Figure 1 — Le feature engineering itératif, au cœur du pipeline ML.
2. Transformations numériques
Les variables numériques peuvent être transformées pour corriger l’asymétrie, réduire l’effet des outliers, ou lineariser des relations.
Transformations courantes
| Transformation | Usage | Python (pandas) |
|---|---|---|
Logarithme (log(1+x)) | Données asymétriques positives (revenus, prix) | df['log_col'] = np.log1p(df['col']) |
Racine carrée (sqrt) | Comptages (accidents, ventes) | df['sqrt_col'] = np.sqrt(df['col']) |
| Box-Cox | Normalisation paramétrique | scipy.stats.boxcox |
| Mise à l’échelle (StandardScaler) | Centrage-réduction pour SVM, régression | from sklearn.preprocessing import StandardScaler |
| Normalisation (MinMaxScaler) | Ramener dans [0,1] pour les réseaux de neurones | from sklearn.preprocessing import MinMaxScaler |
Exemple
import pandas as pd
import numpy as np
df['prix_log'] = np.log1p(df['prix']) # gestion des zéros
df['taille_sqrt'] = np.sqrt(df['taille'])3. Encodage des variables catégorielles
Les algorithmes de ML ne comprennent pas directement du texte. Il faut encoder les catégories en nombres.
Principales méthodes
| Méthode | Principe | Quand l’utiliser | Inconvénient |
|---|---|---|---|
| One‑hot encoding | Crée une colonne binaire par catégorie | Faible cardinalité (< 20 catégories) | Explosion du nombre de colonnes |
| Label encoding | Assigne un entier à chaque catégorie | Modèles arborescents (Random Forest, XGBoost) | Introduit un ordre artificiel |
| Target encoding | Remplace la catégorie par la moyenne de la cible | Modèles linéaires, cardinalité élevée | Risque d’overfitting (nécessite lissage) |
| Frequency encoding | Remplace par la fréquence de la catégorie | Modèles linéaires, cardinalité élevée | Perte d’information sur la cible |
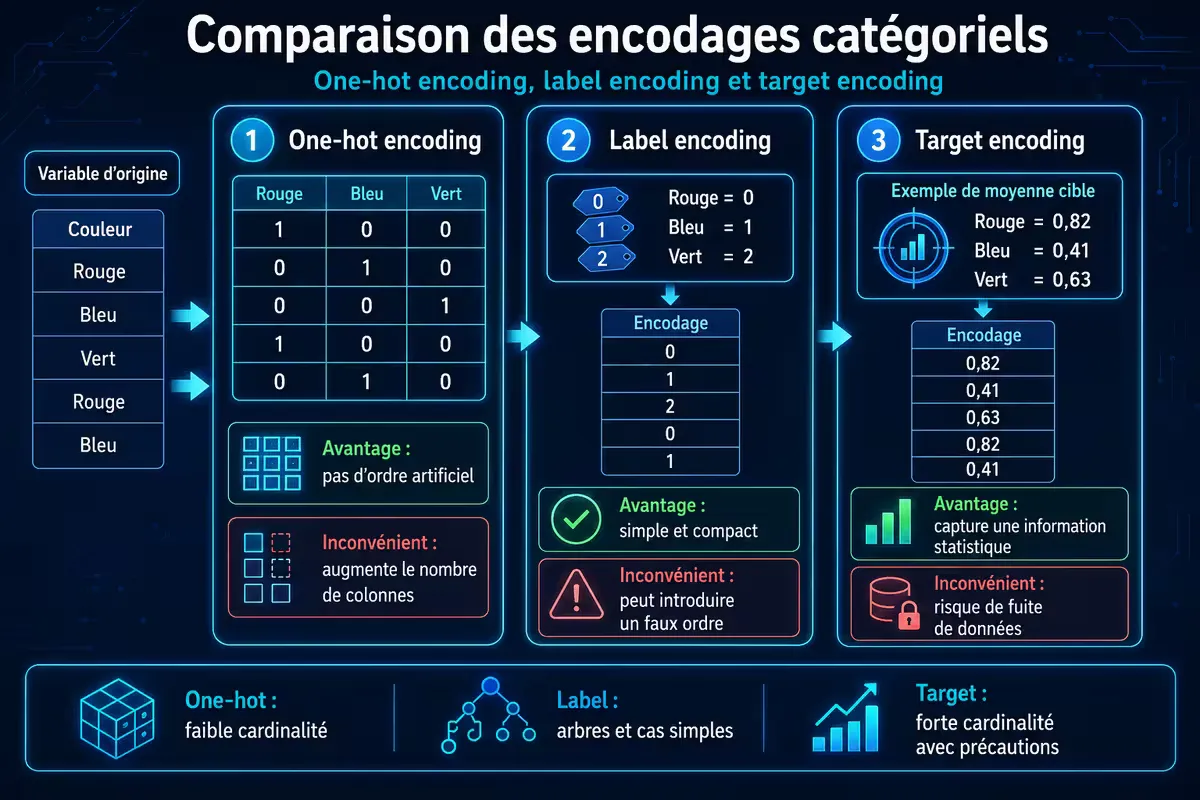
Figure 2 — Les trois principales méthodes d’encodage catégoriel et leurs effets.
Exemple avec scikit-learn
from sklearn.preprocessing import OneHotEncoder
encoder = OneHotEncoder(sparse_output=False)
encoded = encoder.fit_transform(df[['ville']])
# Avec target encoding (category_encoders)
import category_encoders as ce
encoder = ce.TargetEncoder()
df['ville_target'] = encoder.fit_transform(df['ville'], df['cible'])4. Création de features d’interaction et polynomiales
Lorsque l’effet d’une variable dépend d’une autre, on crée une feature d’interaction.
Interactions simples
superficie * prix_m2(taille × prix unitaire)age * sexe(effet différent selon le sexe)
df['surface_prix'] = df['surface'] * df['prix_m2']Features polynomiales
Pour modéliser des relations non linéaires, on ajoute les carrés, cubes, etc.
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2, include_bias=False)
df_poly = poly.fit_transform(df[['age', 'revenu']])Cela génère : age, revenu, age^2, revenu^2, age * revenu.
⚠️ Attention à l’explosion combinatoire ( n_features^degree ).
5. Extraction à partir des dates et textes
Dates
Une colonne date (ex: date_achat) peut se transformer en :
df['annee'] = df['date'].dt.year
df['mois'] = df['date'].dt.month
df['jour'] = df['date'].dt.day
df['jour_semaine'] = df['date'].dt.dayofweek # lundi=0
df['est_weekend'] = df['jour_semaine'].isin([5,6]).astype(int)
df['nb_jours_depuis'] = (reference_date - df['date']).dt.daysTexte (NLP simple)
- Longueur du texte :
df['longueur'] = df['commentaire'].str.len() - Nombre de mots :
df['nb_mots'] = df['commentaire'].str.split().str.len() - Présence d’un mot-clé :
df['contient_urgence'] = df['commentaire'].str.contains('urgent')
6. Binning et discrétisation
Transformer une variable continue en catégories (bins) peut aider les modèles non linéaires et rendre les résultats plus interprétables.
# discrétisation en quantiles (même nombre d’observations)
df['age_groupe'] = pd.qcut(df['age'], q=4, labels=['jeune', 'jeune adulte', 'adulte', 'senior'])
# discrétisation à largeur fixe
bins = [0, 18, 35, 60, 100]
df['age_classe'] = pd.cut(df['age'], bins=bins, labels=['-18', '19-35', '36-60', '60+'])7. Features d’agrégation et statistiques par groupe
Quand les données ont une structure hiérarchique (ex: clients avec plusieurs achats), on peut agréger par groupe.
# Par client, calculer le montant moyen, le total, le nombre d’achats
agg = df.groupby('client_id').agg(
montant_moyen = ('montant', 'mean'),
montant_total = ('montant', 'sum'),
nb_achats = ('montant', 'count')
)
df_client = df_client.merge(agg, on='client_id', how='left')Ces features sont très puissantes pour la prédiction (ex: score de fidélité).
8. Automatisation et pipelines
Pour éviter le data leakage et rendre le feature engineering reproductible, utilisez des pipelines scikit-learn.
from sklearn.pipeline import Pipeline
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
preprocessor = ColumnTransformer(
transformers=[
('num', StandardScaler(), ['age', 'revenu']),
('cat', OneHotEncoder(), ['ville', 'sexe'])
])
pipeline = Pipeline(steps=[
('preprocessor', preprocessor),
('classifier', LogisticRegression())
])
pipeline.fit(X_train, y_train)Pour des transformations plus avancées, Feature-engine offre des transformers dédiés (ex: LogTransformer, MeanEncoder).
9. Bonnes pratiques et pièges
✅ Bonnes pratiques
- Validez chaque feature sur un jeu de validation : supprimez celles qui n’apportent aucun gain.
- Itérez : feature engineering → modèle → analyse des erreurs → nouvelle feature.
- Documentez : chaque transformation doit pouvoir être expliquée à un non initié.
- Utilisez des pipelines pour éviter le data leakage et faciliter la mise en production.
- Pour les grands volumes, privilégiez des transformations vectorisées (pandas/numpy) plutôt que des boucles.
❌ Pièges à éviter
- Utiliser des statistiques globales pour créer une feature (ex:
df['moyenne'] = df['col'].mean()) – c’est du data leakage si fait avant le split. - Oublier de gérer les valeurs manquantes après les transformations (certaines créent des NaN).
- Créer trop de features sans sélection (risque de surapprentissage et de lenteur).
- Ignorer la signification métier : une feature doit avoir un sens. Une combinaison purement mathématique n’est pas toujours utile.
À retenir : Le feature engineering est un processus itératif et créatif. Combinez la connaissance métier, les tests statistiques et la validation croisée pour ne garder que les features qui améliorent vraiment votre modèle.
Revenir au guide complet
Cet article fait partie du guide complet sur la Data Science.
Articles connexes
FAQ
Qu’est-ce que le feature engineering ?
Le feature engineering est le processus de transformation des données brutes en variables (features) plus représentatives du problème sous-jacent, afin d’améliorer les performances des modèles de machine learning. Cela inclut la création de nouvelles variables, la transformation de variables existantes, l’encodage de variables catégorielles et la mise à l’échelle.
Quelle est la différence entre feature engineering et feature selection ?
Le feature engineering crée de nouvelles variables à partir des données existantes. La feature selection consiste à choisir un sous-ensemble des variables disponibles (existantes ou créées) pour réduire la dimensionnalité. Les deux sont complémentaires.
Quels sont les types de transformations courantes ?
Transformations numériques (log, racine carrée, Box-Cox), encodage de variables catégorielles (one-hot, label, target encoding), création d’interactions (produit, somme), extraction de dates (jour de semaine, mois, heure), binning (discrétisation), variables polynomiales, et agrégations par groupe.
Le feature engineering est-il encore utile avec le deep learning ?
Oui, mais à un degré moindre. Les réseaux de neurones profonds peuvent apprendre automatiquement certaines représentations (ex: embeddings). Cependant, un bon feature engineering réduit la complexité du modèle, accélère l’entraînement, et améliore la généralisation, même pour le deep learning.
Quels outils Python pour le feature engineering ?
pandas est la base (apply, map, groupby, transform). scikit-learn propose des transformers (PolynomialFeatures, KBinsDiscretizer, OneHotEncoder, StandardScaler). Feature-engine (bibliothèque dédiée) et category_encoders (encodages avancés) sont très utiles. Pour les séries temporelles, tsfresh.
Comment éviter le data leakage lors du feature engineering ?
Toutes les transformations qui dépendent des statistiques des données (moyenne, écart-type, bornes des classes) doivent être ajustées sur l’ensemble d’entraînement uniquement, puis appliquées au test. Utilisez des pipelines scikit-learn avec `fit` sur l’entraînement et `transform` sur le test.
Sources
- Kaggle – Feature engineering tutorials
- scikit-learn – Feature engineering documentation
- Feature-engine – User guide
- « Feature Engineering for Machine Learning » (O’Reilly, 2018)
Article mis à jour le 14 juin 2026.