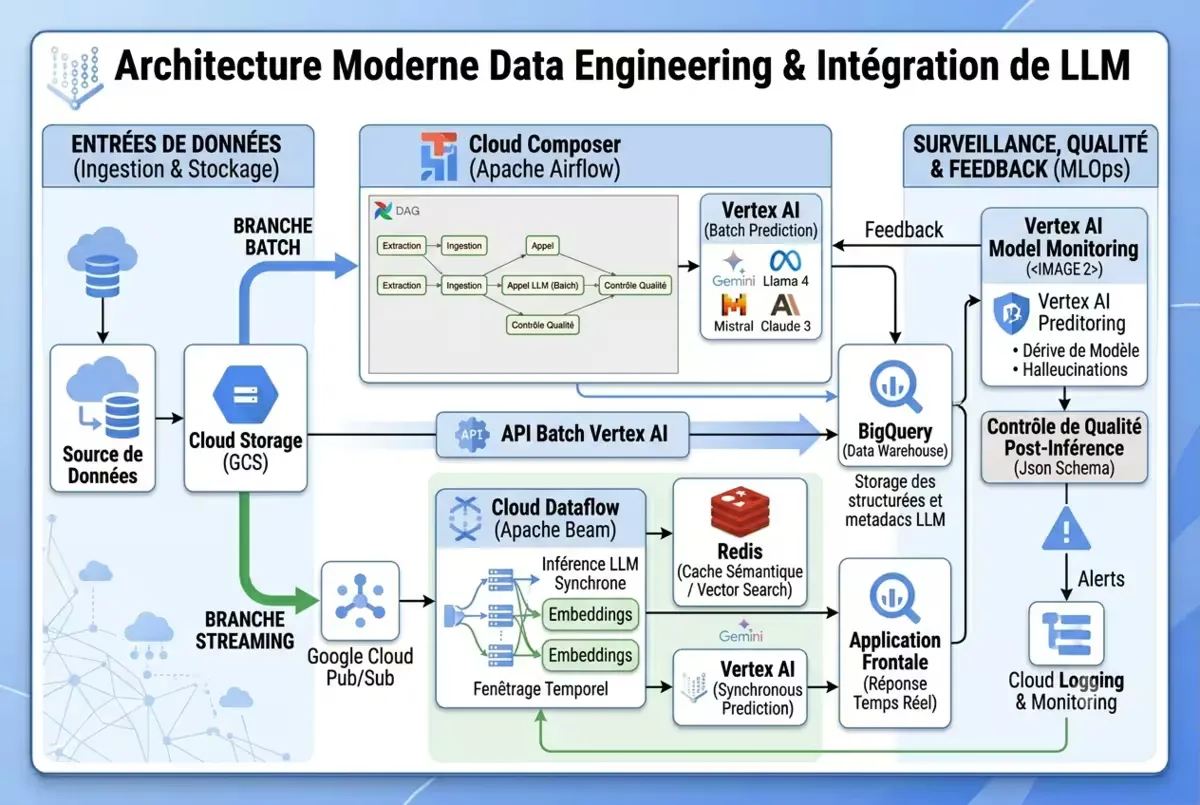
Figure — Schéma d’architecture moderne data engineering + LLM (BigQuery, Composer, Dataflow, Vertex AI)
Intégrer un LLM dans un pipeline de données ne relève plus de l’expérimentation en 2026 : c’est une attente métier standard. Pourtant, la majorité des projets échouent non pas sur le modèle, mais sur l’architecture sous-jacente.
Résumé
Cet article technique détaille les architectures de référence pour intégrer des LLM (Gemini, GPT-5, Claude, Llama 4) dans des pipelines de données en production. Nous couvrons : (1) les trois patterns dominants (batch asynchrone, streaming événementiel, workflow agentique) ; (2) l’orchestration avec Airflow/Composer et Beam/Dataflow ; (3) le caching sémantique pour réduire les coûts de 40 à 70 % ; (4) le monitoring multidimensionnel ; (5) les retours d’expérience de mise en production. Une attention particulière est portée aux coûts, à la sécurité et aux pièges fréquents.
Table des matières
- Pourquoi les architectures ETL classiques ne suffisent plus
- Les trois patterns d’architecture LLM en production
- Orchestration : Airflow, Dataflow, ou les deux ?
- Implémentation détaillée sur Google Cloud
- Gestion des coûts : caching, batching et sélection de modèle
- Monitoring : la dérive des LLM est multidimensionnelle
- Sécurité et conformité : traçabilité et secrets
- Cas concret : pipeline de scoring de tickets support
- FAQ
Pourquoi les architectures ETL classiques ne suffisent plus
Un pipeline ETL classique (Extract-Transform-Load) repose sur trois postulats qui volent en éclats avec les LLM.
Postulat 1 : la transformation est déterministe
Avec SQL ou Python, 2 + 2 donne toujours 4. Un LLM peut donner 4, le résultat est 4, quatre ou parfois je ne sais pas selon la température et le prompt. L’architecture doit tolérer une certaine variance.
Postulat 2 : la latence est prévisible
Une transformation Spark sur 1 million de lignes prendra 12 minutes, plus ou moins 10 %. Un appel LLM peut prendre 200 ms comme 8 secondes, selon la charge du fournisseur, la longueur du contexte et la complexité de la génération.
Postulat 3 : le coût est lié au calcul, pas aux données
Dans l’ETL classique, le coût dépend du temps CPU/GPU. Avec les LLM, le coût dépend du volume de tokens — qui varie selon la longueur des documents d’entrée et la verbosité des réponses. Une même requête peut coûter 5x plus cher si le LLM décide de développer sa réponse.
À retenir : Un pipeline LLM doit être conçu pour l’asynchronie, la tolérance aux pannes (retry avec backoff), et la contrôlabilité des coûts. Les outils du data engineering classique restent pertinents, mais leur assemblage diffère.
Les trois patterns d’architecture LLM en production
Trois patterns architecturaux dominent les déploiements 2026. Le choix dépend de votre contrainte principale.
Pattern 1 : Batch processing asynchrone (volume)
Cas d’usage : scorer 10 millions de commentaires clients une fois par nuit.
Architecture :
- Source : BigQuery / Cloud Storage (documents stockés)
- Orchestrateur : Cloud Composer (Airflow) qui déclenche un job Dataflow
- Traitement : Dataflow Beam lit les documents, les découpe en batches, appelle l’API Vertex AI (LLM) de manière asynchrone via des requêtes parallélisées contrôlées
- Sink : résultats réécrits dans BigQuery
Contrôle de flux : utilisez rated_requests sur l’API LLM pour ne pas dépasser les quotas. Pour Gemini, la limite par défaut est 300 requêtes par minute. Au-delà, implémentez une file d’attente interne.
import apache_beam as beam
from apache_beam.utils.retry import with_retry
class CallLLMDoFn(beam.DoFn):
def __init__(self, project_id, location, model_name):
self.project_id = project_id
self.location = location
self.model_name = model_name
self.client = None
def start_bundle(self):
from google.cloud import aiplatform
aiplatform.init(project=self.project_id, location=self.location)
self.client = aiplatform.gapic.PredictionServiceClient()
@with_retry(max_retries=3, backoff_factor=2.0)
def process(self, element):
# Implémenter un rate limiter (ex: token bucket)
response = self.client.predict(
endpoint=f"projects/{self.project_id}/locations/{self.location}/publishers/google/models/{self.model_name}",
instances=[{"content": element['text']}]
)
return [{'id': element['id'], 'prediction': response.predictions[0]}]Pattern 2 : Streaming événementiel (latence)
Cas d’usage : analyser en quasi-temps réel des conversations de support client.
Architecture :
- Source : Pub/Sub (messages entrants)
- Processor : Dataflow streaming, fenêtrage fixe de 5 secondes, agrégation, appel LLM sur la fenêtre
- Sink : résultat vers BigQuery (analyse historique) + Pub/Sub (alerte si détection d’insatisfaction)
Spécificités : l’état (state) de Dataflow est crucial pour agréger les messages avant appel LLM. Utilisez beam.WindowInto(FixedWindows(5)) et beam.CombineGlobally().
Pattern 3 : Workflow agentique (complexité)
Cas d’usage : assistant IA qui doit interroger une base SQL, appeler une API métier, puis synthétiser.
Architecture : le LLM orchestrate lui-même les appels via un framework agentique (LangChain, Semantic Kernel, Vertex AI Agent Builder). Le pipeline de données devient dynamique : le chemin d’exécution dépend des décisions du LLM.
Piège fréquent : ne pas mettre de garde-fous (guardrails). Un agent peut boucler indéfiniment ou appeler une API de suppression en production. Implémentez un maximum d’étapes et des validateurs de sécurité.
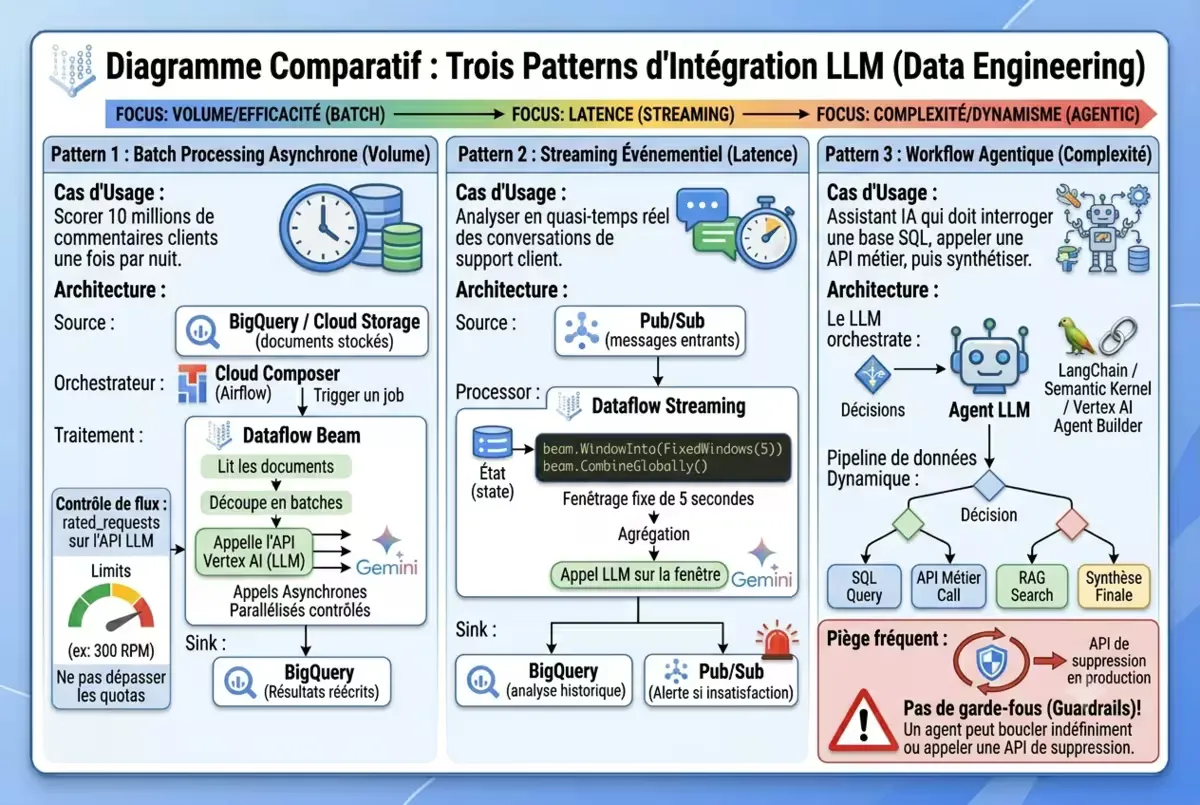
Figure — Les trois patterns dominants d’intégration des LLM dans les pipelines de données en 2026.
Orchestration : Airflow, Dataflow, ou les deux ?
La question récurrente : “Dois-je utiliser Airflow (Cloud Composer) ou Beam (Dataflow) pour mon pipeline LLM ?”
Réponse : les deux, mais pas pour les mêmes tâches.
| Outil | Usage principal | Pour les LLM spécifiquement |
|---|---|---|
| Cloud Composer (Airflow) | Orchestration déclarative de tâches — déclencher, attendre, gérer les dépendances | Planifier les jobs batch, gérer les retries, notifier en cas d’échec, orchestrer les étapes pré/post traitement |
| Dataflow (Beam) | Traitement distribué à grande échelle, streaming ou batch | Paralléliser des millions d’appels LLM, gérer le fenêtrage temporel, maintenir l’état (state) entre les événements |
Bonnes pratiques : Airflow orchestre une tâche qui est “déclencher un job Dataflow”. Dataflow fait le travail lourd. N’essayez pas d’appeler un LLM depuis une tâche Airflow (sauf pour des tests unitaires) — vous perdez la parallélisation et la reprise sur échec fine.
Pour les workflows agentiques, ni Airflow ni Dataflow ne sont adaptés (trop rigides). Utilisez plutôt un framework agentique (LangChain, Semantic Kernel) déployé sur Cloud Run ou Vertex AI, avec Airflow pour orchestrer les traitements batch périphériques (ex. réindexation vectorielle hebdomadaire).
Implémentation détaillée sur Google Cloud
Prenons un cas réel : pipeline de classification automatique de tickets support en 5 catégories, avec 500 000 tickets par jour.
Composants
- Source : Cloud Storage (fichiers JSON bruts) et BigQuery (table
tickets_raw) - Orchestrateur : Cloud Composer (Airflow) — DAG déclenché toutes les 2 heures
- Prétraitement : Dataflow job Beam — nettoie et tokenize les textes
- Appel LLM : Vertex AI (Gemini 1.5 Flash, le modèle plus léger/rapide pour ce cas)
- Post-traitement : Dataflow job Beam — parse les réponses JSON du LLM
- Sink : BigQuery — tables
tickets_classifiedetllm_traces
Extrait du DAG Airflow (Cloud Composer 3)
from airflow import DAG
from airflow.providers.google.cloud.operators.dataflow import DataflowStartFlexTemplateOperator
from airflow.providers.google.cloud.operators.bigquery import BigQueryInsertJobOperator
from airflow.providers.google.cloud.sensors.dataflow import DataflowJobStatusSensor
with DAG('llm_classification_pipeline', schedule='0 */2 * * *') as dag:
preprocess = DataflowStartFlexTemplateOperator(
task_id='preprocess_texts',
location='europe-west1',
project_id='iana-data',
body={
'launch_parameter': {
'jobName': 'preprocess-tickets',
'containerSpecGcsPath': 'gs://dataflow-templates/preprocess.json',
'parameters': {
'input_table': 'iana-data.tickets.raw',
'output_gcs': 'gs://temp/tickets_clean/'
}
}
}
)
wait_preprocess = DataflowJobStatusSensor(
task_id='wait_preprocess',
job_id="{{ task_instance.xcom_pull('preprocess')['job_id'] }}"
)
call_llm = DataflowStartFlexTemplateOperator(
task_id='call_llm_batch',
body={
'launch_parameter': {
'jobName': 'llm-inference-tickets',
'parameters': {
'input_gcs': 'gs://temp/tickets_clean/',
'model': 'gemini-1.5-flash',
'project_id': 'iana-data'
}
}
}
)
# Et ainsi de suite...Gestion des erreurs et retry
Les LLM échouent de manière non déterministe (timeout, rate limit, réponse mal formée). Votre pipeline doit en tenir compte.
class LLMCallWithDLQ(beam.DoFn):
def process(self, element):
try:
result = call_llm(element['text'])
yield beam.TaggedOutput('success', {'id': element['id'], 'result': result})
except Exception as e:
yield beam.TaggedOutput('dead_letter', {'id': element['id'], 'error': str(e)})Les échecs alimentent une table BigQuery dead_letter_queue pour reprise manuelle ou automatique.
Gestion des coûts : caching, batching et sélection de modèle
La facture LLM peut exploser si vous ne maîtrisez pas le volume de tokens.
Stratégie 1 : Cache sémantique vectoriel
De nombreuses requêtes sont similaires. Au lieu d’appeler le LLM, interrogez une base vectorielle (Vertex AI Vector Search, Pinecone, pgvector) pour vérifier si une question équivalente a déjà reçu une réponse.
Résultat : réduction de 40 à 70 % des appels pour les cas récurrents.
Stratégie 2 : Batching intelligent
Les LLM ont des coûts fixes par appel + coût variable par token. Grouper 10 petits documents en un seul appel peut diviser le coût par 3.
Attention : la latence augmente (le LLM doit traiter plus de tokens). Un compromis : batches de 3 à 5 documents.
Stratégie 3 : Sélection dynamique du modèle
Pour 80 % des requêtes simples (ex. classification en 3 classes), utilisez un petit modèle (Gemini 1.5 Flash, GPT-4o mini). Pour les 20 % de requêtes complexes (raisonnement multi-étapes), basculez sur un gros modèle (Gemini 3.1 Pro, Claude 4.5 Sonnet).
Implémentation : un classifieur simple (par regex ou petit modèle) décide du modèle à utiliser.
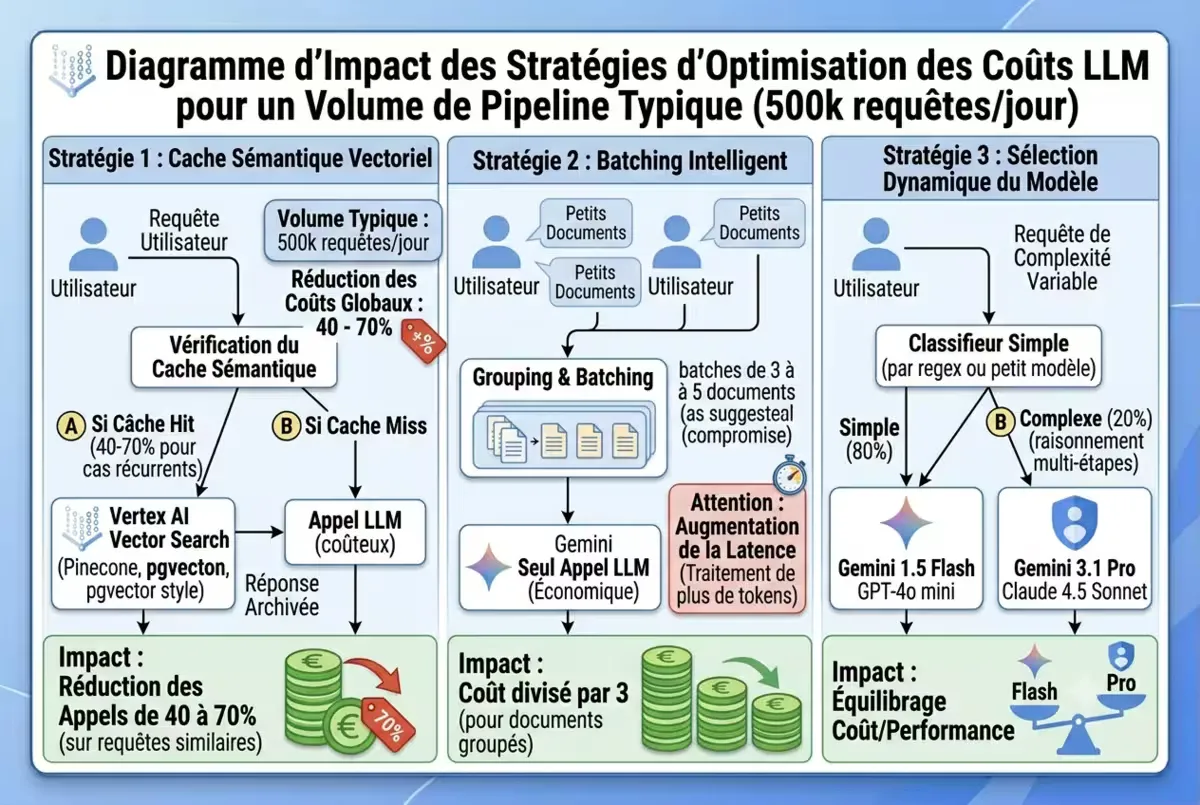
Figure — Impact des stratégies d’optimisation sur les coûts LLM pour un volume typique de pipeline (500k requêtes/jour).
Exemple de calcul de coût
Pour 500 000 tickets, avec un texte moyen de 500 tokens input et une réponse de 50 tokens output, via Gemini 1.5 Flash ($0.0375/M input, $0.15/M output) :
- Input : 500 × 500 000 = 250M tokens → coût : 250 × $0.0375 = $9.375
- Output : 50 × 500 000 = 25M tokens → coût : 25 × $0.15 = $3.75
- Total brut : ~$13.125 par 500k tickets
Avec un cache vectoriel à 60 % : $5.25 pour la même charge. Le coût marginal par ticket tombe à ~$0.00001.
Monitoring : la dérive des LLM est multidimensionnelle
Un modèle classique dérive sur la distribution des features ou la cible. Un LLM dérive sur quatre dimensions.
Dimension 1 : Dérive lexicale (distribution des tokens)
Les tokens (sous-mots) que le LLM génère peuvent changer dans le temps — sans que le sens s’altère nécessairement. Un pipeline robuste suit l’évolution de la fréquence des tokens.
Dimension 2 : Dérive sémantique
La similarité cosinus entre les embeddings de réponses sur des requêtes stables (ex. “Expliquez ce qu’est une dérive de concept”) ne doit pas chuter sous 0.85.
Dimension 3 : Dérive comportementale (latence et refus)
Suivez la latence p95 et le taux de refus (“Je ne peux pas répondre”). Une hausse peut indiquer un durcissement des garde-fous du fournisseur.
Dimension 4 : Dérive métier (hallucinations)
Sur un sous-ensemble de données annotées (200 exemples par semaine), mesurez le taux d’hallucination (affirmation non présente dans le contexte).
SelfCheckGPT : méthode sans vérité terrain pour estimer l’hallucination. Générez plusieurs réponses à la même question, mesurez leur consistance. Si elles se contredisent, forte probabilité d’hallucination.
Implémentation sur Vertex AI Model Monitoring
Vertex AI permet de configurer des seuils d’alerte sur les dérives de features. Pour les LLM, utilisez des feature attributions spécifiques : longueur de la réponse, score de logit moyen, entropie de la distribution des tokens.
Sécurité et conformité : traçabilité et secrets
Gestion des secrets
Ne faites jamais :
# À ne PAS faire !
API_KEY = "AIzaSyD..."Faites plutôt :
from google.cloud import secretmanager
def get_secret(secret_id):
client = secretmanager.SecretManagerServiceClient()
response = client.access_secret_version(name=secret_id)
return response.payload.data.decode('UTF-8')Injectez l’identité via Workload Identity (GKE, Cloud Run, Composer) ou les métadonnances d’instance (Compute Engine, Dataflow).
Traçabilité des appels
Pour chaque appel LLM, enregistrez dans une table llm_audit_log :
request_id(uuid)user_idoupipeline_nameinput_tokens,output_tokens,latency_msmodel_nameetmodel_versionresponse(tronquée si PII)cost_estimatetimestamp
Cette table servira pour la facturation interne, le debugging et les audits réglementaires (RGPD, AI Act).
Pour approfondir les enjeux de gouvernance des données, l’article sur la protection des données personnelles dans les pipelines IA complète ces aspects techniques.
Cas concret : pipeline de scoring de tickets support
Mettons en pratique l’ensemble des concepts avec un exemple réel.
Contexte
Une plateforme SaaS reçoit 500 000 tickets support par mois. Objectif : classifier automatiquement en 5 catégories (Facturation, Technique, Compte, Produit, Autre) avec une fiabilité > 85 %, et extraire le sentiment (positif/négatif/neutre).
Architecture retenue
- Ingestion : tickets entrants vers Pub/Sub
- Streaming : Dataflow job fenêtré (fenêtre de 5 minutes) pour prétraitement et appel Gemini 1.5 Flash
- Batch hebdomadaire : Airflow déclenche un job d’évaluation sur un échantillon de 1000 tickets annotés manuellement
- Stockage : BigQuery (tables
tickets_predictions,llm_audit_log,drift_metrics) - Monitoring : Vertex AI Model Monitoring + alertes Pub/Sub vers Slack
Résultats après 3 mois
| Métrique | Avant pipeline | Après pipeline |
|---|---|---|
| Temps moyen de classification | 45 min (humain) | 4 secondes (automatique) |
| Coût par ticket | $0,45 | $0,0004 (dont $0,00015 d’appels LLM) |
| Taux de reprise humaine (cas complexes) | 100 % | 12 % |
| Satisfaction client (classification correcte) | N/A | 89 % |
Leçons apprises
- Commencer avec le modèle le plus rapide : Gemini 1.5 Flash a suffi pour 80 % des cas. Les modèles “Pro” sont réservés aux 20 % restants via un routeur.
- Le cache vectoriel a été la clé : 58 % de taux de hit après 2 semaines, divisant les coûts par 2,4.
- La dead letter queue est indispensable : 0,3 % des appels échouent pour des raisons variées (timeout, malformé). Sans DLQ, ces tickets étaient perdus.
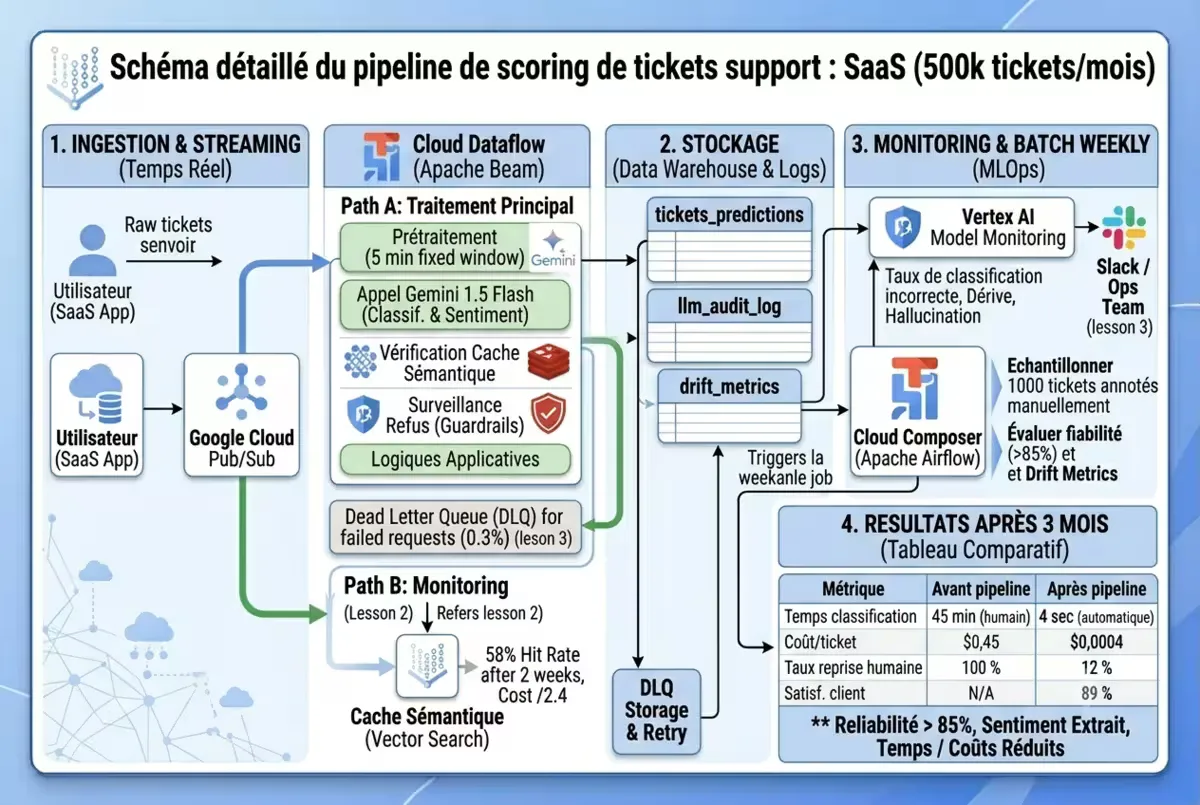
Figure — Architecture détaillée du pipeline de scoring de tickets support en production sur Google Cloud.
FAQ
Quelle est la différence entre un pipeline ETL classique et un pipeline intégrant des LLM ?
La différence principale réside dans la gestion de l'asynchronie et du non-déterminisme. Les LLM ont des latences variables (de quelques centaines de millisecondes à plusieurs secondes selon la taille du contexte) et produisent des résultats statistiques. Un pipeline classique (ETL/ELT) attend des transformations déterministes et des temps de réponse stables. L'architecture de données doit donc intégrer des files d'attente (Pub/Sub, Kafka), des mécanismes de retry avec backoff exponentiel pour gérer les limitations de taux (Rate Limits), et des étapes de validation post-inférence (pydantic/Json Schema).
Comment estimer les coûts d'un pipeline LLM à grande échelle ?
La formule de base est : coût = (volume tokens input × prix input) + (volume tokens output × prix output). Pour Gemini 1.5 Pro, comptez environ $1.25/M tokens input et $3.75/M tokens output (pour des contextes standards). À cela s'ajoutent les coûts de calcul d'orchestration (Cloud Composer/Airflow), de stockage des traces et logs, et de cache en mémoire. Une excellente pratique consiste à implémenter un cache sémantique vectoriel qui intercepte les requêtes similaires en amont, réduisant la facture de 40 à 70 % sur les charges de travail récurrentes.
Quels sont les patterns d'architecture les plus éprouvés pour les pipelines LLM ?
Trois patterns majeurs se distinguent : (1) le **Batch Processing asynchrone** pour le scoring ou l'extraction d'entités sur de gros volumes de documents stockés (idéal via l'API Batch de Vertex), (2) le **Streaming événementiel** (Pub/Sub + Dataflow) avec fenêtrage pour traiter des flux de données ou de messages en quasi-temps réel, et (3) les **Workflows Agentiques** où le LLM orchestre de manière dynamique des appels à des outils (bases SQL, API, Vector Search).Le choix dépend de vos contraintes de latence, de volume et de budget.
Comment monitorer la dérive d'un LLM en production ?
La dérive d'un LLM est multidimensionnelle et se surveille à trois niveaux : (1) **La dérive des entrées (Input Drift)** en analysant la distribution spatiale des embeddings des requêtes utilisateurs ; (2) **La dérive sémantique des sorties** en mesurant la similarité cosinus des réponses face à un jeu de questions de test invariables ; (3) **Les métriques de performance et de qualité opérationnelle**, telles que la latence P95 (soumise aux variations de charge GPU) et le taux de refus ou d'hallucinations évalué par des frameworks de LLM-as-a-Judge (ex: Prometheus, SelfCheckGPT).
Quels outils d'orchestration sont recommandés pour les pipelines LLM ?
Pour les charges Batch et Streaming, le couple **Cloud Composer (Apache Airflow)** pour l'orchestration de tâches globales et **Dataflow (Apache Beam)** pour le traitement de données distribuées à l'échelle offre la plus grande maturité. Pour les logiques applicatives hautement dynamiques ou agentiques (boucles de décision LLM), des frameworks comme LangGraph ou Vertex AI Agent Builder viennent compléter le pipeline. La règle d'or reste d'éviter les appels LLM synchrones et bloquants au sein de micro-services sans découplage par une file d'attente intermédiaire.
Comment gérer l'authentification et la sécurité des clés API LLM ?
Aucune clé API ou identifiant ne doit transiter en clair. Utilisez un gestionnaire de secrets d'entreprise (**Google Secret Manager**) combiné à des identités fédérées via **Workload Identity**. Dans Airflow (Cloud Composer), configurez le hook `SecretManagerBackend` pour une résolution transparente des connexions. Pour Dataflow, appuyez-vous sur les Application Default Credentials (ADC) liés au compte de service du worker. Enfin, journalisez de manière immuable l'ensemble des accès aux modèles via des journaux d'audit (Audit Trails) à des fins de conformité.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
Revenir au guide complet
Cet article fait partie du guide complet sur le Data Engineering qui couvre l’ensemble des architectures, outils et patterns pour le traitement de données à grande échelle.
Sources
- Google Cloud (2026) – Architecting LLM pipelines with Dataflow and Vertex AI
- Apache Beam (2026) – State and timers for streaming LLM inference
- Gartner (2026) – Best practices for LLM integration in data pipelines
- dbt Labs (2026) – Semantic caching for LLM applications
- ACM (2025) – SelfCheckGPT: Zero-resource hallucination detection
- Google Cloud Tech Blog (mars 2026) – Running cost-effective LLM inference at scale