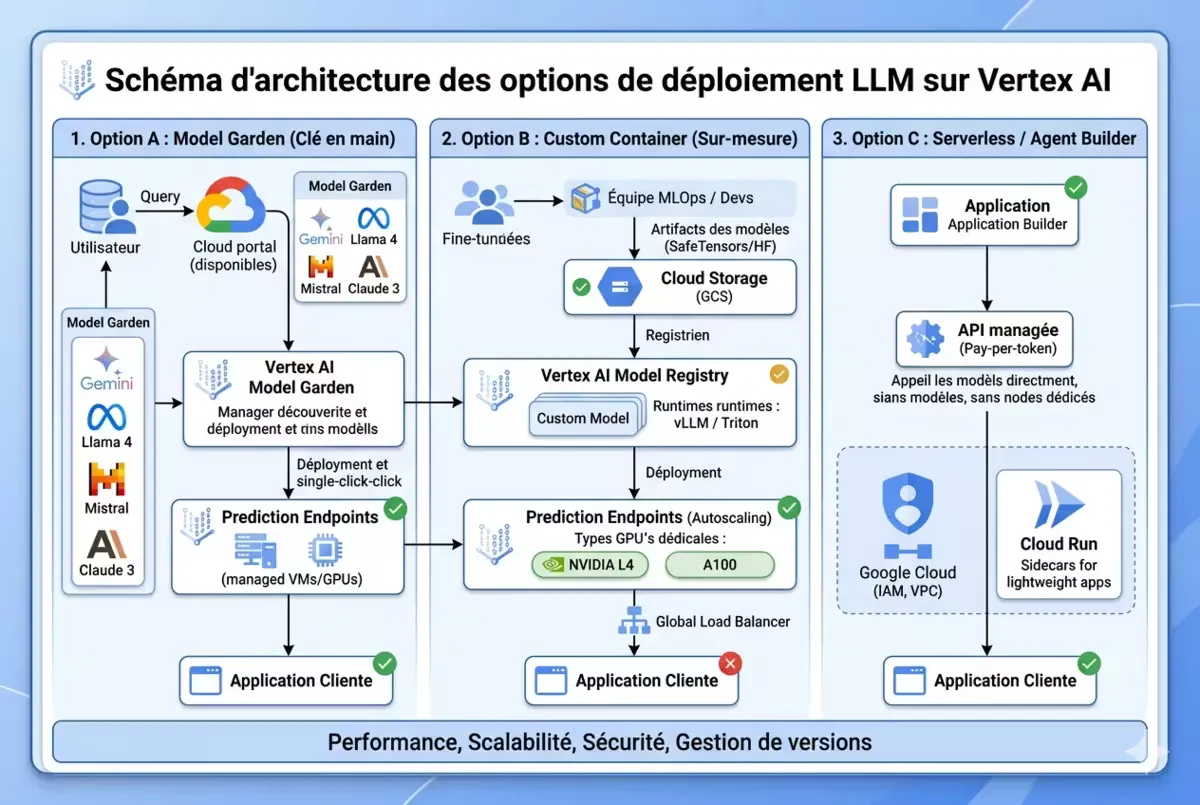
Figure — Les trois voies de déploiement des LLM sur Vertex AI.
Déployer un LLM en production est devenu un enjeu central du data engineering. Google Cloud Vertex AI propose un écosystème complet — mais encore faut-il savoir naviguer entre ses options.
Résumé
Cet article est un guide technique pour déployer et mettre à l’échelle des LLM (Gemini, Llama 4, Mistral, Claude 3, modèles fine-tunés) sur Google Cloud Vertex AI. Nous couvrons : (1) les trois voies de déploiement (Model Garden, custom container, serverless), (2) les stratégies de scaling (GPU, autoscaling, multi-région), (3) l’optimisation des coûts (batching, cache, selection de modèle), (4) le monitoring des LLM en production, (5) l’intégration dans des pipelines de données avec BigQuery et Dataflow. Des exemples de code et des retours d’expérience concrets jalonnent l’article.
Table des matières
- Pourquoi Vertex AI plutôt que l’API directe ?
- Les trois voies de déploiement LLM sur Vertex AI
- Model Garden : déployer Gemini, Llama 4, Mistral en quelques clics
- Custom container : déployer vos propres LLM fine-tunés
- Stratégies de scaling pour l’inférence LLM
- Optimisation des coûts : batching, cache, model selection
- Monitoring d’un LLM en production sur Vertex AI
- Intégration pipeline : BigQuery, Dataflow, Vertex AI
- Cas concret : déploiement d’un LLM de support client
- FAQ
Pourquoi Vertex AI plutôt que l’API directe ?
La question revient systématiquement. L’API Gemini directe est simple : une clé, un endpoint HTTP, et vous générez des réponses. Alors pourquoi ajouter la couche Vertex AI ?
| Critère | API Gemini directe | Vertex AI |
|---|---|---|
| Démarrage | 5 minutes | 30 minutes |
| Monitoring dérive | Aucun | Intégré (data drift, concept drift) |
| Gestion versions | Manuelle | Model Registry natif |
| Audit logs | Basique | Intégration Cloud Audit Logs + IAM fin |
| Fine-tuning | Limité (modèles petits) | Support complet (tous modèles) |
| Modèles tiers (Llama, Mistral) | Non | Oui (Model Garden) |
| Intégration VPC / Private IP | Non | Oui |
| Coût unitaire par requête | $ | $$ (mais mieux maîtrisé) |
À retenir : L’API directe pour les prototypes, les tests unitaires, ou les usages personnels. Vertex AI pour toute mise en production impliquant plusieurs développeurs, des contraintes de conformité, ou des volumes significatifs.
Les trois voies de déploiement LLM sur Vertex AI
Google Cloud structure le déploiement des LLM autour de trois voies, de la plus simple à la plus flexible.
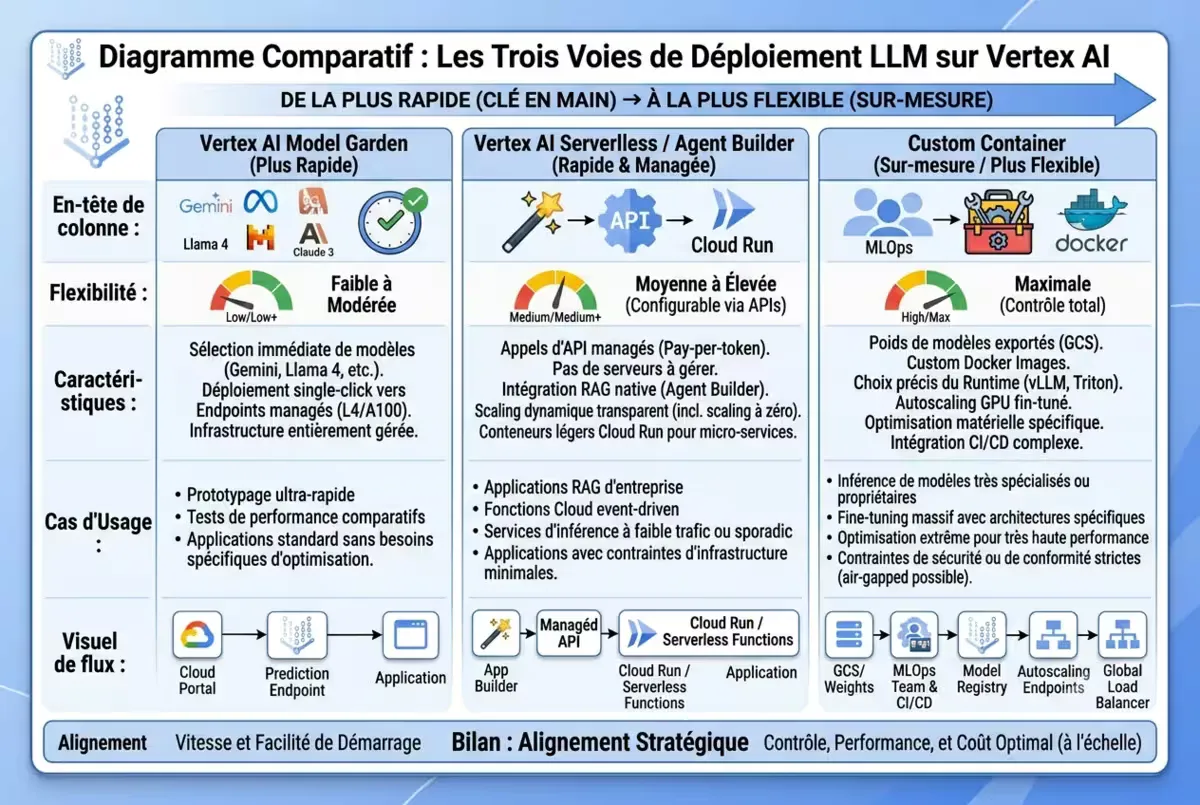
Figure — Les trois voies de déploiement des LLM sur Vertex AI, de la plus rapide (Model Garden) à la plus flexible (Custom Container).
Voie 1 : Model Garden (recommandée pour 80 % des cas)
Model Garden est un catalogue de modèles pré-entraînés, prêts au déploiement en quelques clics ou lignes de code.
Modèles disponibles en 2026 :
- Gemini 1.5 Flash, Pro, 3.1 Pro
- Llama 4 (9B, 90B, 405B)
- Mistral 7B, Mixtral 8x7B
- Claude 3 Haiku, Sonnet, Opus
- CodeGemma, RecurrentGemma
Pour chaque modèle, Vertex AI gère automatiquement :
- L’infrastructure GPU/TPU sous-jacente
- L’autoscaling
- Le monitoring de base
- La mise à jour des versions
Voie 2 : Custom container (modèles fine-tunés ou exotiques)
Vous avez fine-tuné Llama 4 sur vos données, ou vous voulez déployer un modèle non listé dans Model Garden ? Utilisez un conteneur personnalisé.
Prérequis :
- Conteneur Docker respectant l’interface de prédiction Vertex AI (HTTP sur port 8080)
- Ou utiliser vLLM/Triton avec l’adaptateur officiel
Voie 3 : Serverless (trafic sporadique)
Pour les prototypes, les pipelines batch occasionnels, ou les applications appelées quelques fois par jour. Vertex AI déploie le modèle sur Cloud Run, qui scale à 0. La première requête subit un cold start (2-10 secondes), mais vous ne payez que pour les invocations.
Model Garden : déployer Gemini, Llama 4, Mistral en quelques clics
Model Garden est la porte d’entrée la plus simple. Voici un exemple de déploiement programmatique de Llama 4 via l’API Vertex AI.
from google.cloud import aiplatform
aiplatform.init(project='iana-data', location='us-central1')
# Déployer Llama 4 90B depuis Model Garden
model = aiplatform.Model.upload(
display_name="llama4-90b-instruct",
artifact_uri="gs://vertex-ai-model-garden/llama4/90b/", # modèles pré-packagés
serving_container_image_uri="us-docker.pkg.dev/vertex-ai/vertex-ai/llama4:latest"
)
endpoint = model.deploy(
machine_type="a2-highgpu-1g", # 1 GPU A100
accelerator_type="NVIDIA_TESLA_A100",
accelerator_count=1,
min_replica_count=1,
max_replica_count=4,
traffic_split={"0": 100}
)Déploiement de Gemini via Model Garden
Gemini est un modèle propriétaire, son déploiement est encore plus simple :
from vertexai.generative_models import GenerativeModel
model = GenerativeModel("gemini-1.5-pro-002")
response = model.generate_content(
"Analyse le sentiment de ce ticket support : ...",
generation_config={
"temperature": 0.2,
"max_output_tokens": 500,
}
)Ce mode n’est pas un “déploiement” au sens classique (Google gère l’inférence), mais il bénéficie des avantages de Vertex AI : monitoring, quotas, fine-tuning possible.
Bon plan : Gemini 1.5 Flash a le meilleur rapport latence/coût pour la plupart des cas d’usage. Réservez Gemini 3.1 Pro aux tâches nécessitant du raisonnement complexe ou de très longs contextes (>1M tokens).
Custom container : déployer vos propres LLM fine-tunés
Vous avez fine-tuné un modèle sur vos données (ex. instruction tuning de Llama 4 9B sur des tickets support). Voici comment le déployer.
Étape 1 : Exporter le modèle fine-tuné
# Exemple avec Hugging Face + vLLM
from vllm import LLM, SamplingParams
model = LLM(model="./fine-tuned-llama4-support")
# Sauvegarder les poids au format Safetensors
model.save("gs://my-bucket/fine-tuned-models/llama4-support/")Étape 2 : Créer un conteneur compatible Vertex AI
Utilisez l’image de base us-docker.pkg.dev/vertex-ai/vertex-ai/prediction/tf2-cpu.2-15:latest pour le CPU, ou les images GPU spécifiques.
FROM us-docker.pkg.dev/vertex-ai/vertex-ai/prediction/pytorch-gpu.2-6:latest
# Installation de vLLM pour l'inférence haute performance
RUN pip install vllm==0.6.0
# Copie du script de prédiction
COPY predictor.py /opt/model/predictor.py
ENV AIP_STORAGE_URI="gs://my-bucket/fine-tuned-models/llama4-support/"
ENV AIP_HEALTH_ROUTE="/health"
ENV AIP_PREDICT_ROUTE="/predict"
CMD ["python", "/opt/model/predictor.py"]Étape 3 : Déployer sur Vertex AI
model = aiplatform.Model.upload(
display_name="llama4-support-finetuned",
artifact_uri="gs://my-bucket/fine-tuned-models/llama4-support/",
serving_container_image_uri="gcr.io/iana-data/llama4-support:latest",
serving_container_predict_route="/predict",
serving_container_health_route="/health",
serving_container_ports=[8080],
)
endpoint = model.deploy(
machine_type="g2-standard-24", # 1 GPU L4 (plus économique)
accelerator_type="NVIDIA_L4",
accelerator_count=1,
min_replica_count=1,
max_replica_count=5,
)Stratégies de scaling pour l’inférence LLM
La scalabilité d’un endpoint LLM dépend de trois variables : le nombre de requêtes, la longueur des tokens, et la complexité du modèle.
Choix des accélérateurs (GPU / TPU)
| GPU | Cas d’usage | Coût relatif |
|---|---|---|
| L4 | Inférence économique pour modèles < 30B | 1x |
| A100 (40GB) | Modèles 30B-70B, haute performance | 3-4x |
| A100 (80GB) | Modèles 70B+ ou grand contexte | 4-5x |
| H100 | Très gros modèles (Llama 4 405B), raisonnement complexe | 8-10x |
| TPU v5e | Modèles optimisés pour JAX/TensorFlow, très gros volumes | Sur devis |
Configuration de l’autoscaling
endpoint.deploy(
...,
min_replica_count=1, # Au moins 1 nœud en permanence
max_replica_count=10, # Jusqu'à 10 nœuds en pic
scaling_params={
"scaling_strategy": "CPU_UTILIZATION", # ou "REQUEST_COUNT"
"target_utilization": 70, # Déclencher scaling à 70% CPU
}
)Scaling multi-régional
Pour les applications mondiales avec > 500 requêtes/seconde, envisagez de déployer des endpoints dans plusieurs régions (us-central1, europe-west4, asia-southeast1) et d’utiliser un Global Load Balancer avec routage basé sur la latence.
Optimisation des coûts : batching, cache, model selection
La facture d’inférence LLM peut rapidement s’envoler. Voici trois stratégies éprouvées.
Stratégie 1 : Batching dynamique
Au lieu d’appeler le LLM pour chaque requête séparément, regroupez-les.
from vertexai.preview.batch_prediction import BatchPredictionJob
job = BatchPredictionJob.submit(
source_model="gemini-1.5-flash",
input_dataset="gs://bucket/input/*.jsonl",
output_dataset="gs://bucket/output/",
batch_size=64, # 64 requêtes par lot
)Gain : jusqu’à 40 % de réduction du coût par token.
Stratégie 2 : Cache sémantique vectoriel
Pour les requêtes récurrentes (ex. “Quel est le délai de livraison standard ?”), stockez la réponse dans une base vectorielle et interrogez-la avant d’appeler le LLM.
# Vérification d'existence dans le cache
query_embedding = embed_model.embed(query_text)
similar = vector_search.find_neighbors(query_embedding, k=1, distance_threshold=0.85)
if similar:
return similar['cached_response']
else:
response = llm.generate(query_text)
vector_search.upsert(embeddings=[query_embedding], metadata=[response])Gain : 50 à 70 % d’appels évités, facture divisée par 2 ou 3.
Stratégie 3 : Sélection dynamique du modèle
Toutes les requêtes n’ont pas besoin d’un gros modèle.
def route_to_model(user_query):
# Classifieur simple (basé sur longueur, présence de mots-clés techniques)
if "code" in user_query and len(user_query) > 500:
return "gemini-3.1-pro" # Modèle cher, performant
elif is_urgent_ticket(user_query):
return "gemini-1.5-flash" # Modèle rapide, économique
else:
return "gemini-1.5-flash" # Par défautGain : 80 % des requêtes vont au petit modèle, 20 % au gros → réduction de 60 % de la facture.
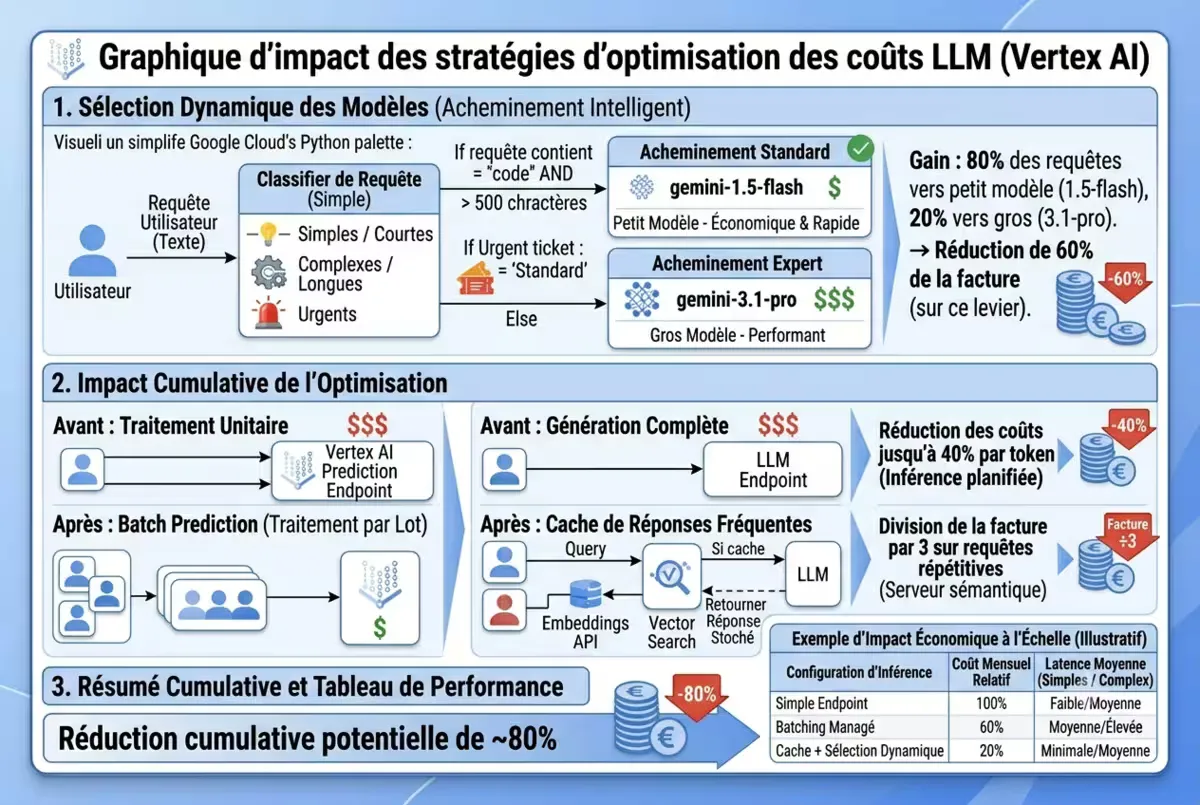
Figure — Réduction des coûts d’inférence LLM grâce au batching, au cache vectoriel et à la sélection dynamique de modèle.
Monitoring d’un LLM en production sur Vertex AI
Vertex AI fournit des métriques de base. Pour un LLM, complétez-les.
Métriques automatiques (Vertex AI)
- Latence (p50, p95, p99)
- Nombre de requêtes
- Taux d’erreurs (HTTP 4xx, 5xx)
- Utilisation CPU/GPU
Métriques LLM spécifiques à implémenter
class LLMMetricsLogger:
def log_inference(self, request_id, input_text, output_text, model_name):
metrics = {
"input_tokens": count_tokens(input_text),
"output_tokens": count_tokens(output_text),
"output_length": len(output_text),
"has_unknown_tokens": detect_unknown_tokens(output_text),
"refusal_detected": "I cannot answer" in output_text
}
# Écrire dans BigQuery via l'API
write_to_bigquery("llm_inference_logs", metrics)Alertes recommandées
| Seuil | Action |
|---|---|
| Latence p95 > 2s pendant 10 min | Alerte Slack, vérifier scaling |
| Taux de refus > 5 % sur 1 heure | Vérifier garde-fous, peut indiquer dérive |
| Input tokens moyen > 2x baseline | Revoir le prompt engineering |
Pour une approche plus large, les architectures modernes de data engineering détaillent l’intégration de ces métriques dans des dashboards BigQuery + Looker.
Intégration pipeline : BigQuery, Dataflow, Vertex AI
Un LLM seul n’est qu’une API. La puissance vient de son insertion dans des pipelines de données.
Pipeline typique : scoring batch de documents BigQuery
from airflow import DAG
from airflow.providers.google.cloud.operators.bigquery import BigQueryInsertJobOperator
from airflow.providers.google.cloud.operators.vertex_ai.batch import VertexAIBatchPredictOperator
with DAG('batch_llm_scoring', schedule='0 2 * * *') as dag:
extract = BigQueryInsertJobOperator(
task_id='extract_tickets',
configuration={
'query': {
'query': 'SELECT id, text FROM tickets WHERE date >= DATE_SUB(CURRENT_DATE(), INTERVAL 1 DAY)',
'destinationTable': {'projectId': 'iana-data', 'datasetId': 'temp', 'tableId': 'batch_input'},
'writeDisposition': 'WRITE_TRUNCATE'
}
}
)
predict = VertexAIBatchPredictOperator(
task_id='llm_batch_predict',
model_name='gemini-1.5-flash',
input_gcs='gs://temp/batch_input.jsonl',
output_gcs='gs://temp/batch_output/'
)
load = BigQueryInsertJobOperator(
task_id='load_results',
configuration={
'load': {
'sourceUris': ['gs://temp/batch_output/*'],
'destinationTable': {'projectId': 'iana-data', 'datasetId': 'support', 'tableId': 'llm_classifications'}
}
}
)
extract >> predict >> loadPipeline streaming : analyse de chat en temps réel
# Dataflow Beam pipeline avec fenêtrage
with beam.Pipeline() as p:
messages = p | "Read from Pub/Sub" >> beam.io.ReadFromPubSub(subscription=subscription)
windowed_messages = messages | "Window" >> beam.WindowInto(FixedWindows(10))
scored = windowed_messages | "Call Vertex AI" >> beam.ParDo(CallVertexAIDoFn())
scored | "Write to BigQuery" >> beam.io.WriteToBigQuery(table=table)
L’intégration de ces pipelines avec les meilleurs outils d’IA du marché permet de choisir le modèle adapté à chaque étape.
Cas concret : déploiement d’un LLM de support client
Prenons une situation réelle : une plateforme de e-commerce déploie un assistant support multilingue.
Spécifications
- Volume : 200 000 conversations / jour
- Latence requise : < 800 ms (conversation synchrone)
- Langues : FR, EN, ES, DE
- Modèle : Gemini 1.5 Flash (multilingue, 2M tokens contexte)
Architecture retenue
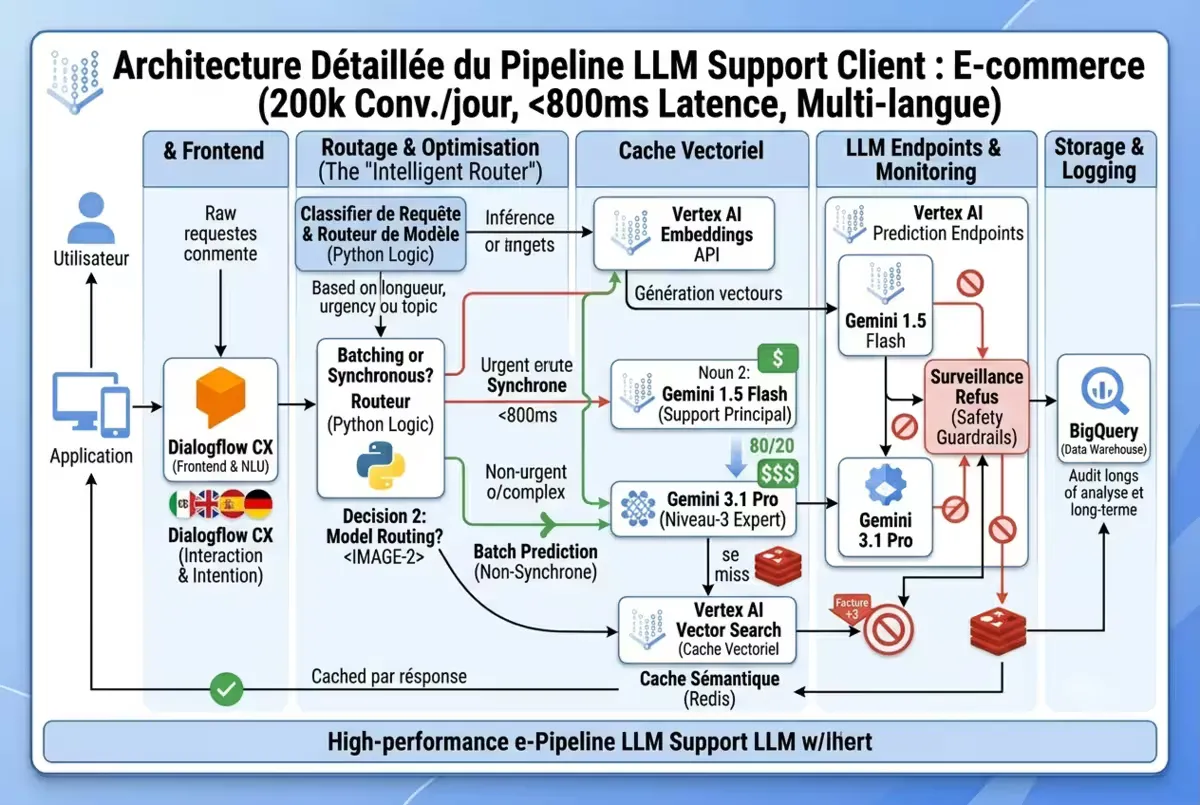
Figure — Architecture de production pour assistant support LLM avec Vertex AI.
Configuration du endpoint
endpoint = model.deploy(
machine_type="g2-standard-24", # L4 GPU
accelerator_type="NVIDIA_L4",
accelerator_count=2, # 2 GPUs pour la charge
min_replica_count=5, # Pool de 5 en idle
max_replica_count=50, # Scaling jusqu'à 50
traffic_split={"0": 100}
)Résultats après 3 mois
| Métrique | Valeur |
|---|---|
| Latence p95 | 620 ms |
| Taux de résolution en un tour | 78 % |
| Coût mensuel (modèle + infrastructure) | $4 200 pour 200k conversations/j |
| Réduction des tickets escalade humaine | -62 % |
Leçons apprises
- Cache vectoriel indispensable : 40 % des questions sont récurrentes (FAQ produit, livraison). Le cache a divisé les appels LLM.
- Gemini 1.5 Flash suffit : les tentatives de passage à Gemini 3.1 Pro ont augmenté la latence sans améliorer la satisfaction.
- Surveiller les refus : Gemini refusait certaines questions support légitimes (ex. “annuler commande”). Ajustement du prompt et fine-tuning léger ont résolu le problème.
Pour aller plus loin sur le fine-tuning des LLM sur des données métier, l’article sur les pipelines data engineering pour LLM détaille la phase d’entraînement et d’évaluation.
FAQ
Quelles sont les options pour déployer un LLM sur Vertex AI ?
Vertex AI propose trois voies principales : (1) **Model Garden** : déploiement en un clic ou accès via API Pay-per-token pour les modèles leaders (Gemini, Llama 4, Mistral, Claude 3). (2) **Custom container** : pour vos modèles personnalisés via des runtimes optimisés (vLLM, Triton). (3) **Serverless / Cloud Run** : pour les architectures micro-services avec mise à l'échelle à zéro pour les usages sporadiques.
Comment scaler un endpoint Vertex AI pour un LLM à fort trafic ?
La scalabilité repose sur trois leviers : l'autoscaling horizontal (ajout de nœuds GPU selon l'utilisation CPU/GPU), le choix des puces (GPU L4 pour l'inférence économique, A100/H100 pour la performance, TPU v5e pour les volumes massifs), et le batching dynamique des requêtes. Pour des pics à 1000+ requêtes/seconde, déployez des endpoints multi-régionaux derrière un Global Load Balancer.
Comment réduire les coûts d'inférence LLM sur Vertex AI ?
Trois stratégies majeures : (1) le **Pay-per-token** pour les trafics irréguliers (pas de coût de machine au repos), (2) le **Batch Ingestion** : pour les tâches asynchrones, le traitement par lot sur Vertex AI réduit les coûts jusqu'à 40 %, (3) le **cache sémantique** : stocker les embeddings des requêtes fréquentes pour éviter de solliciter le LLM à chaque fois, divisant la facture par 3 sur les requêtes répétitives.
Quelle est la différence entre Vertex AI et un appel direct à l'API Gemini ?
L'API Gemini directe est idéale pour le prototypage rapide. Vertex AI apporte la couche "Enterprise Ready" : gestion fine des accès (IAM), isolation réseau (VPC), monitoring des dérives de données, traçabilité (Audit Logs), pipelines de fine-tuning managés, et accès à un catalogue multi-fournisseurs via le Model Garden.
Comment déployer un modèle Llama 4 fine-tuné sur Vertex AI ?
Exportez vos poids au format Safetensors sur Cloud Storage. Enregistrez le modèle dans le **Vertex AI Model Registry** en associant soit un conteneur préconstruit de Google Cloud optimisé pour l'inférence, soit un conteneur personnalisé (Triton + vLLM). Déployez ensuite sur un endpoint configuré avec des GPU adaptés (comme le NVIDIA L4).
Vertex AI supporte-t-il le RAG (Retrieval-Augmented Generation) ?
Oui, de bout en bout. Via **Vertex AI Agent Builder** et **Vertex AI Search**, vous pouvez connecter vos LLM à vos données d'entreprise (Google Drive, Cloud Storage, bases de données) de manière native. La plateforme gère automatiquement le chunking, la vectorisation (Embeddings API) et la recherche de contexte sans code complexe.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
Revenir au guide complet
Cet article fait partie du guide complet sur les outils IA, Data Science & Big Data qui couvre l’ensemble des plateformes, frameworks et architectures pour la mise en production des modèles.
Sources
- Google Cloud (2026) – Vertex AI documentation: Deploy LLMs from Model Garden
- Google Cloud (2026) – Optimizing LLM inference costs: best practices
- Vertex AI pricing (mai 2026) – GPU instances and inference pricing
- Hugging Face / vLLM (2026) – Deploying custom LLMs on Vertex AI
- Google Cloud Tech Blog (mars 2026) – Scaling Gemini for enterprise support