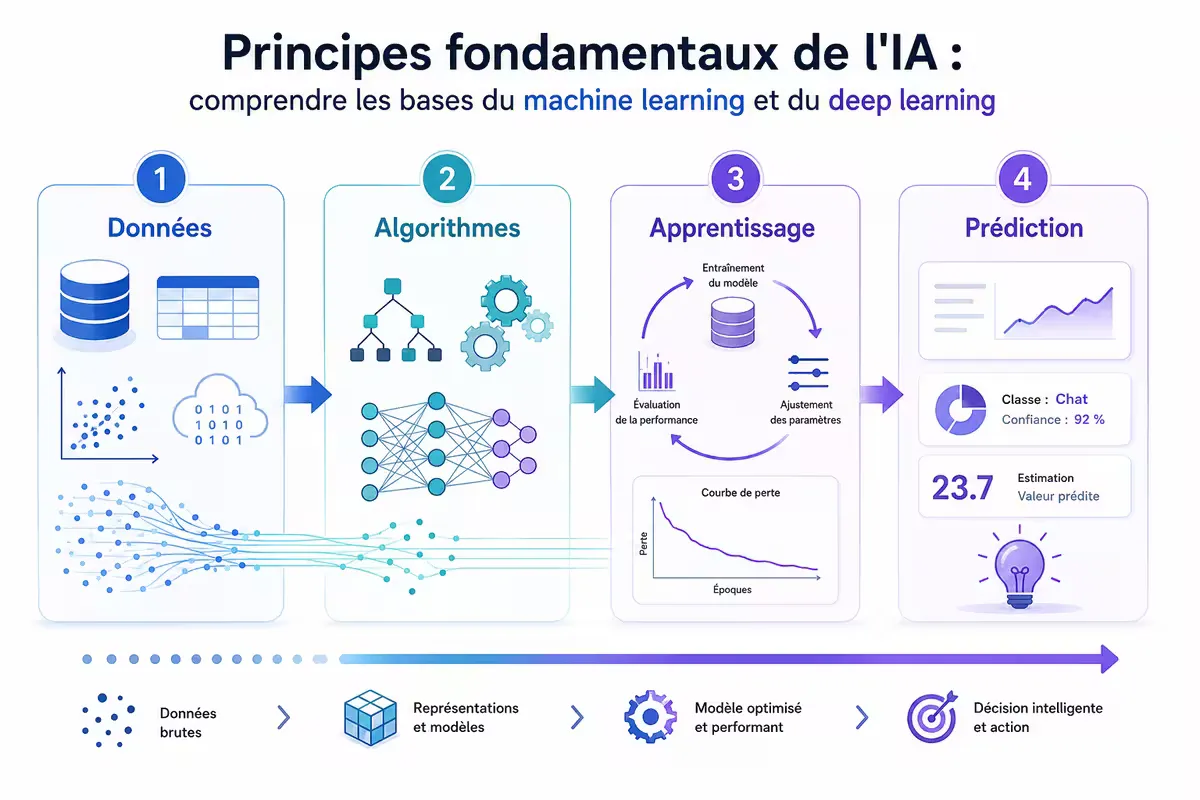
Figure — L’intelligence artificielle repose sur l’interaction entre les données, les algorithmes d’apprentissage et la capacité à généraliser à des situations nouvelles.
L’intelligence artificielle (IA) est entrée dans notre quotidien, des assistants vocaux aux recommandations personnalisées. Mais que se cache-t-il sous ce terme aux contours flous ? Cet article pose les fondations conceptuelles pour comprendre ce qu’est vraiment l’IA — et ce qu’elle n’est pas.
Résumé
Cet article présente les principes fondamentaux sur lesquels repose l’intelligence artificielle contemporaine. Nous couvrons : (1) la définition et la cartographie du domaine (IA, ML, deep learning), (2) les trois paradigmes d’apprentissage (supervisé, non supervisé, par renforcement), (3) l’architecture des réseaux de neurones artificiels, (4) l’algorithme de descente de gradient, moteur de l’apprentissage, (5) les notions de généralisation et de surapprentissage, (6) les limites actuelles de l’IA et ses perspectives. L’article constitue un point d’entrée pour situer la donnée structurée et le data engineering dans l’écosystème plus large de l’IA.
Table des matières
- Qu’est-ce que l’intelligence artificielle ? Définition et périmètre
- La cartographie de l’IA : IA, ML, Deep Learning
- Les trois paradigmes de l’apprentissage automatique
- Le cœur technique : les réseaux de neurones artificiels
- La descente de gradient : le moteur de l’apprentissage
- Généralisation et surapprentissage : l’équilibre fondamental
- Les limites actuelles de l’IA
- Pourquoi la donnée structurée est cruciale
- FAQ
Qu’est-ce que l’intelligence artificielle ? Définition et périmètre
L’intelligence artificielle est un domaine scientifique né dans les années 1950, dont l’objectif est de créer des systèmes capables d’effectuer des tâches qui, si elles étaient réalisées par un humain, seraient considérées comme nécessitant de l’intelligence.
Intelligence Artificielle (IA) : discipline visant à doter les machines de capacités cognitives — perception, raisonnement, apprentissage, planification, compréhension du langage, prise de décision — traditionnellement associées à l’esprit humain.
Deux grandes approches historiques
L’histoire de l’IA a connu deux visions concurrentes :
L’IA symbolique (ou classique) : domine des années 1950 aux années 1980. Elle postule que l’intelligence peut être reproduite par la manipulation de symboles selon des règles logiques. On “programme” explicitement la connaissance (ex. un expert système en diagnostic médical). Limite : l’écriture manuelle des règles ne passe pas à l’échelle.
L’IA connexionniste (ou statistique) : émerge dans les années 1980 et domine aujourd’hui. Elle s’inspire du fonctionnement du cerveau : l’intelligence émerge de l’interaction d’un grand nombre d’unités simples (neurones artificiels) qui apprennent à partir d’exemples. L’essor des données massives et de la puissance de calcul a consacré cette approche.
L’IA moderne que nous utilisons quotidiennement — des moteurs de recommandation aux assistants vocaux — est presque exclusivement connexionniste. Le “deep learning” en est l’expression la plus aboutie.
La cartographie de l’IA : IA, ML, Deep Learning
Sous le terme générique “IA” se cache une hiérarchie de concepts qu’il est essentiel de distinguer.
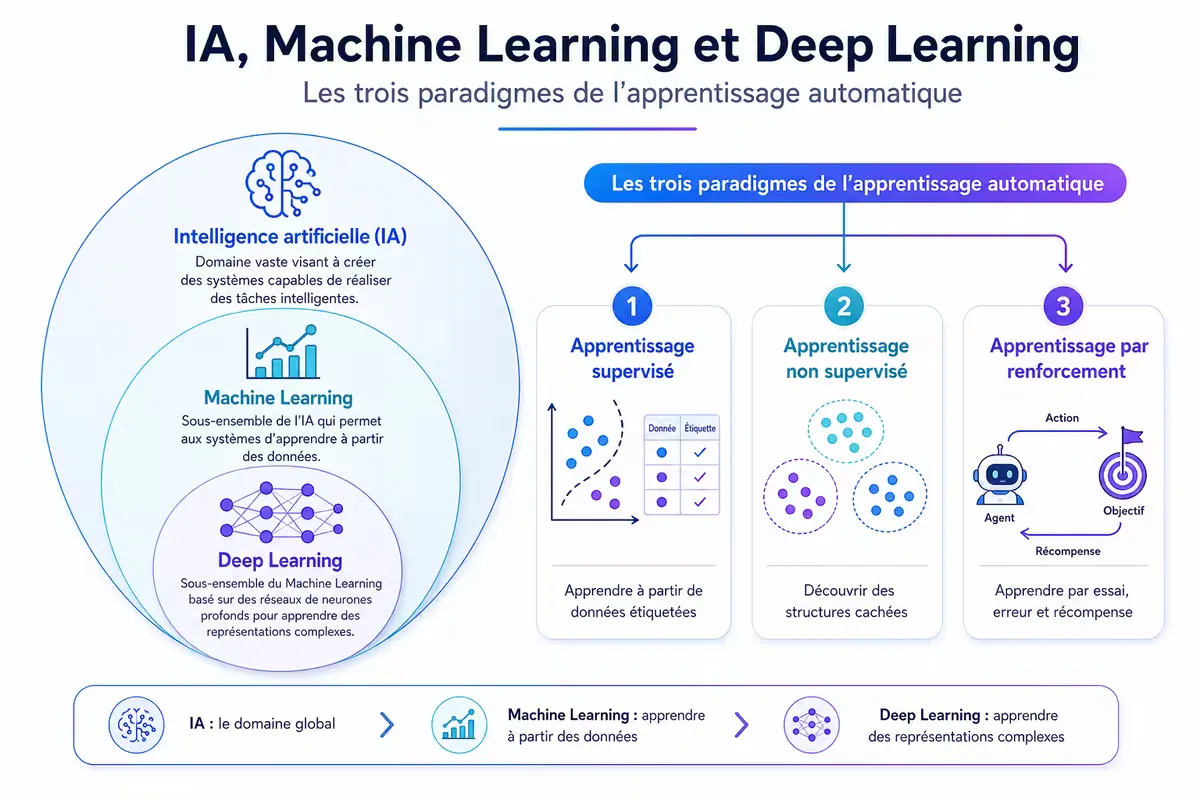
Figure — La hiérarchie de l’IA : le deep learning est un sous-ensemble du machine learning, lui-même sous-ensemble de l’intelligence artificielle.
Intelligence artificielle (IA) — le domaine le plus large
Toute technique visant à simuler l’intelligence, qu’elle soit symbolique, statistique ou hybride.
Machine learning (ML) — apprentissage automatique
Sous-ensemble de l’IA où les systèmes apprennent à partir de données sans être explicitement programmés. L’algorithme identifie des régularités statistiques dans les données d’entraînement et les utilise pour faire des prédictions sur de nouvelles données.
Le ML suit le principe : montrez-moi des exemples, je vais apprendre la règle.
Deep learning (DL) — apprentissage profond
Sous-ensemble du ML utilisant des réseaux de neurones artificiels à plusieurs couches (profondes). Ces architectures permettent d’apprendre automatiquement des représentations hiérarchiques : les premières couches détectent des motifs simples (contours, textures), les couches profondes combinent ces motifs en concepts plus abstraits (objets, visages).
| Niveau | Exemples de techniques |
|---|---|
| IA (large) | Systèmes experts, logique floue, arbres de décision, ML, DL |
| Machine Learning | Régression linéaire, SVM, forêts aléatoires, k-means, DBSCAN |
| Deep Learning | Réseaux convolutifs (CNN), transformers (BERT, GPT), réseaux récurrents (RNN, LSTM) |
Les trois paradigmes de l’apprentissage automatique
L’apprentissage automatique se décline en trois grandes familles, selon la nature des données disponibles.
1. Apprentissage supervisé (supervised learning)
Principe : on dispose d’un jeu de données d’entraînement composé de couples (entrée, sortie attendue). Le modèle apprend à associer chaque entrée à sa bonne sortie.
Métaphore pédagogique : c’est l’apprentissage par un enseignant qui donne les réponses. L’élève (le modèle) s’entraîne sur des exercices corrigés.
Applications typiques :
- Classification (sortie discrète) : reconnaissance d’images (chat/chien), détection de spam (spam/non-spam), diagnostic médical
- Régression (sortie continue) : prévision du prix d’un bien immobilier, estimation de la consommation énergétique
2. Apprentissage non supervisé (unsupervised learning)
Principe : on dispose seulement des entrées, sans sorties associées. Le modèle doit découvrir par lui-même des structures, des similarités ou des groupes dans les données.
Métaphore pédagogique : c’est l’apprentissage sans enseignant. L’élève doit organiser les connaissances par lui-même, en identifiant des catégories implicites.
Applications typiques :
- Clustering (regroupement) : segmentation de clients, catégorisation de documents
- Réduction de dimensionnalité : visualisation de données haute dimension, compression
- Détection d’anomalies : fraude bancaire, panne industrielle
3. Apprentissage par renforcement (reinforcement learning)
Principe : un agent apprend par interaction avec un environnement. Il reçoit des récompenses (positives ou négatives) en fonction de ses actions. L’objectif est d’apprendre une stratégie (politique) qui maximise la récompense cumulée sur le long terme.
Métaphore pédagogique : c’est l’apprentissage par l’action et la conséquence, comme un enfant qui apprend à marcher (tomber est une “récompense négative”).
Applications typiques :
- Jeux (AlphaGo, AlphaZero, jeux vidéo)
- Robotique (apprentissage de la marche, de la saisie)
- Véhicules autonomes
- Optimisation de systèmes complexes (gestion d’énergie, ordonnancement)
À retenir : Le choix du paradigme dépend de la nature des données disponibles. Pas de données étiquetées ? L’apprentissage non supervisé ou par renforcement (si simulation possible) sont des alternatives.
Le cœur technique : les réseaux de neurones artificiels
Les réseaux de neurones artificiels sont l’architecture de base du deep learning moderne. Ils s’inspirent (très librement) du cerveau biologique.
Architecture d’un neurone artificiel
Un neurone artificiel reçoit plusieurs signaux d’entrée, leur applique des poids, somme le tout, ajoute un biais, puis applique une fonction d’activation non linéaire.
Sortie = f(∑(poids_i × entrée_i) + biais)La fonction d’activation (sigmoid, ReLU, tanh) introduit la non-linéarité : sans elle, l’empilement de couches se réduirait à une simple combinaison linéaire.
L’architecture en couches
Un réseau profond (deep neural network) comporte :
- Couche d’entrée : reçoit les données brutes (ex. pixels d’une image)
- Couches cachées : plusieurs couches successives qui transforment progressivement la représentation. Plus elles sont nombreuses, plus le réseau est “profond”
- Couche de sortie : produit la prédiction (ex. probabilité d’appartenir à chaque classe)
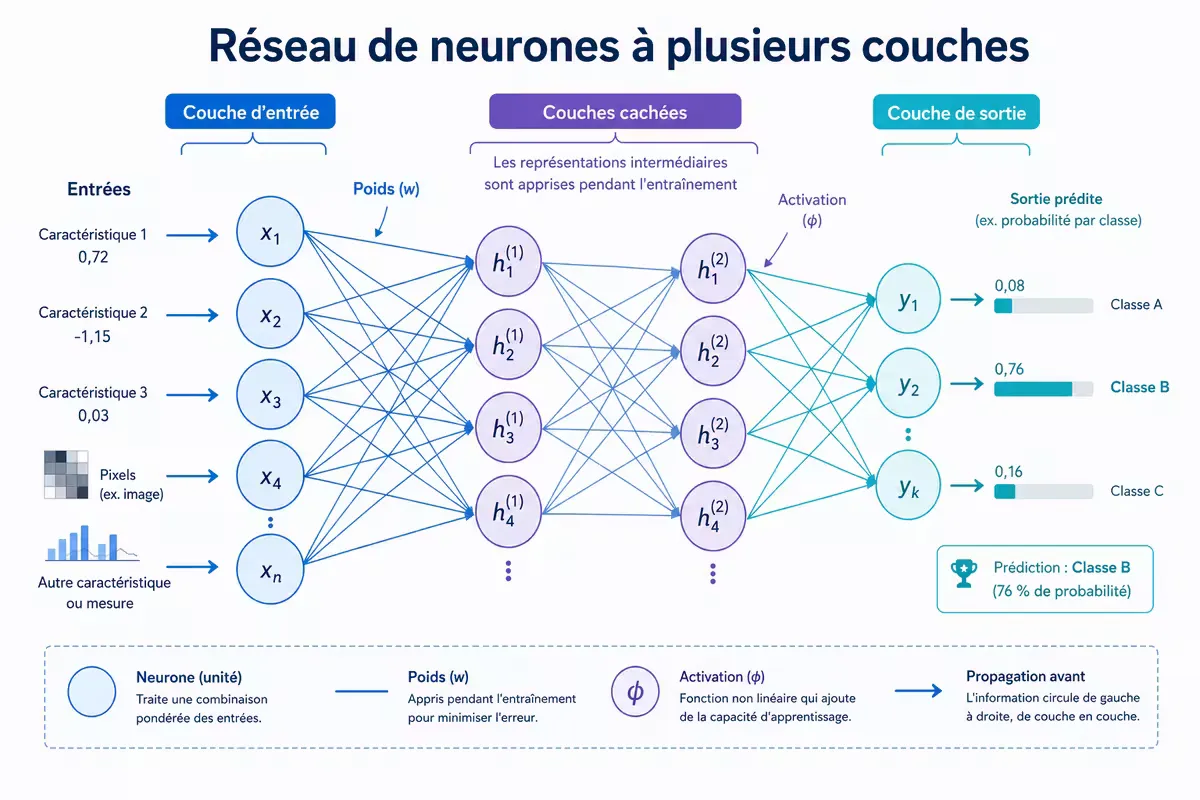
Figure — Architecture simplifiée d’un réseau de neurones profond : les couches successives transforment l’information jusqu’à la prédiction finale.
Pourquoi la profondeur change tout
La puissance du deep learning vient de la hiérarchie des représentations apprises automatiquement :
- Premières couches (proches de l’entrée) : détectent des motifs simples (contours, textures)
- Couches intermédiaires : combinent ces motifs en formes élémentaires (coins, courbes)
- Couches profondes : construisent des concepts complexes (visages, objets, scènes)
Cette capacité à apprendre des représentations par elle-même — sans ingénierie manuelle des caractéristiques (feature engineering) — distingue le deep learning des méthodes classiques de ML.
La descente de gradient : le moteur de l’apprentissage
Comment le réseau apprend-il ? L’algorithme fondamental est la descente de gradient.
Le problème : minimiser l’erreur
On dispose d’une fonction de coût (ou fonction de perte) qui mesure l’écart entre la prédiction du réseau et la valeur attendue. Par exemple, l’erreur quadratique moyenne (MSE) ou l’entropie croisée (cross-entropy). L’apprentissage revient à trouver les paramètres (poids et biais) qui minimisent cette fonction de coût.
L’algorithme : suivre la pente descendante
Si vous êtes au sommet d’une montagne par temps de brouillard et que vous voulez atteindre la vallée, vous avancez dans la direction de la plus forte descente. Le gradient — un vecteur qui indique la direction de la plus forte pente — vous donne cette direction.
À chaque étape d’apprentissage :
- On calcule le gradient de la fonction de coût par rapport aux paramètres
- On ajuste les paramètres en sens inverse du gradient (vers la diminution de l’erreur)
- On répète jusqu’à convergence
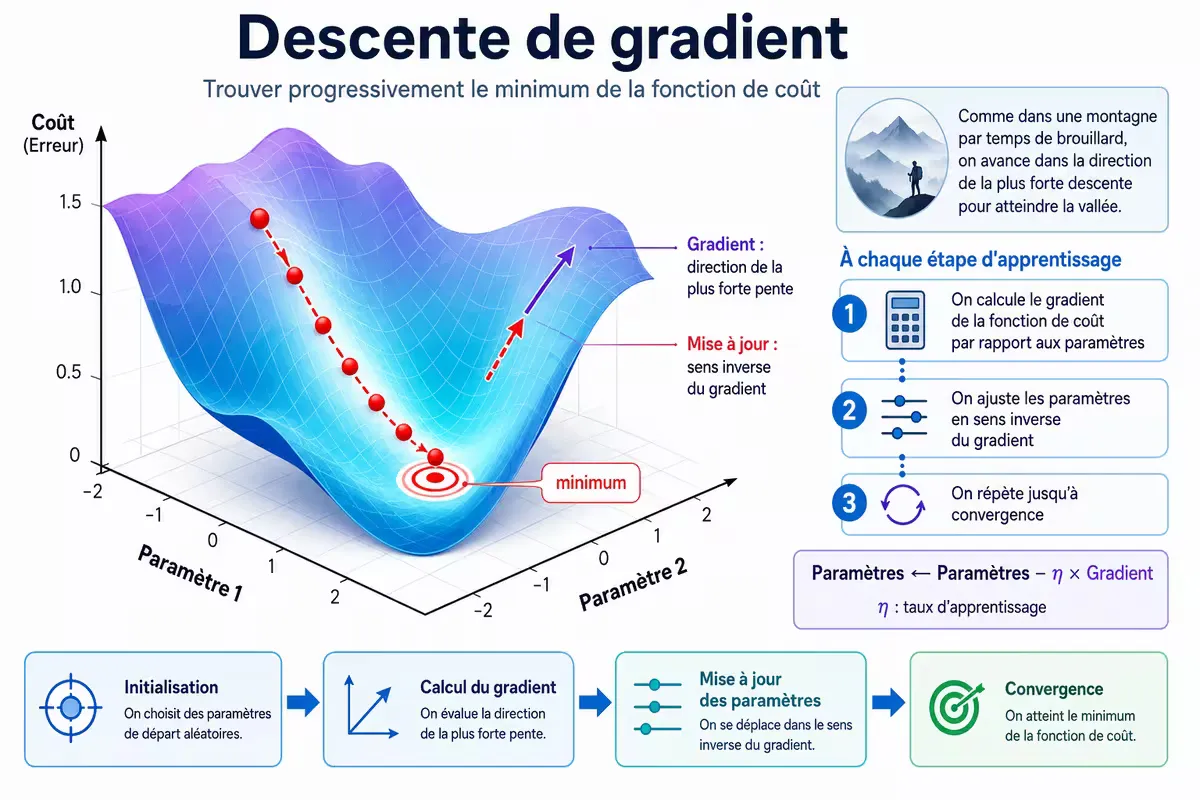
Figure — Visualisation de l’algorithme de descente de gradient : le point (les paramètres du modèle) se déplace progressivement vers le minimum de la fonction de coût.
Rétropropagation (backpropagation)
Dans un réseau profond, le calcul du gradient se fait par rétropropagation : on propage l’erreur de la couche de sortie vers les couches d’entrée, en appliquant la règle de dérivation en chaîne. Cet algorithme, combiné à la descente de gradient, est le socle commun de presque tous les systèmes d’apprentissage profond.
À retenir : L’apprentissage automatique moderne repose sur l’optimisation d’une fonction de coût par descente de gradient. C’est ce mécanisme qui transforme un réseau de neurones aléatoire en un système capable de reconnaître des visages, de traduire des langues ou de conduire une voiture.
Généralisation et surapprentissage : l’équilibre fondamental
La capacité à bien performer sur des données jamais vues est la véritable mesure de l’intelligence d’un modèle.
Surapprentissage (overfitting)
Un modèle surapprend lorsqu’il mémorise par cœur les données d’entraînement — y compris leur bruit — mais échoue à généraliser à de nouvelles données.
Symptômes : performance exceptionnelle sur l’entraînement (ex. 99,9 %), médiocre sur le test (ex. 70 %).
Sous-apprentissage (underfitting)
Un modèle sous-apprend lorsqu’il n’a pas capté la structure des données, même sur l’entraînement.
Symptômes : performance médiocre à la fois sur l’entraînement et le test.
Les techniques de régularisation
Pour atteindre le bon équilibre, on dispose de multiples techniques :
| Technique | Principe |
|---|---|
| Early stopping | Arrêter l’entraînement avant que le modèle ne mémorise le bruit |
| Dropout | Désactiver aléatoirement des neurones pendant l’entraînement pour forcer la redondance |
| Régularisation L1/L2 | Ajouter une pénalité aux poids importants pour favoriser des solutions simples |
| Augmentation de données | Créer artificiellement des variations des exemples d’entraînement |
| Validation croisée | Évaluer sur plusieurs échantillons de validation |
Les limites actuelles de l’IA
Malgré des progrès spectaculaires, l’IA d’aujourd’hui — dite “IA étroite” — présente des limites fondamentales.
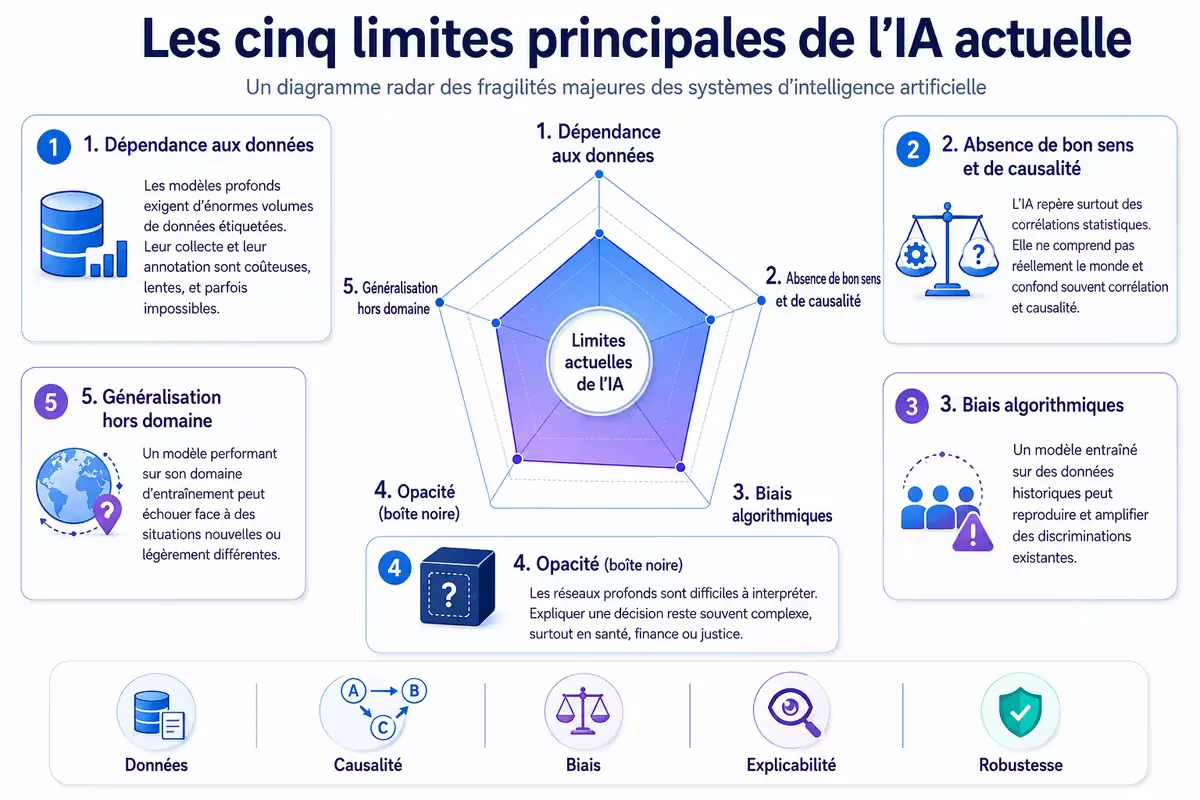
Figure — Les principales limites de l’IA actuelle : chaque axe représente un défi majeur, l’éloignement du centre indiquant la sévérité de la limitation.
Limite 1 : dépendance aux données
Les modèles d’apprentissage profond nécessitent des quantités massives de données étiquetées. L’obtention de ces données (annotation manuelle) est coûteuse et parfois impossible.
Limite 2 : absence de bon sens et de causalité
L’IA ne “comprend” pas le monde. Elle détecte des corrélations statistiques, pas des relations causales. Un modèle peut apprendre que “les personnes qui portent des lunettes réussissent mieux à un test” sans comprendre que l’âge (corrélé aux lunettes et à l’expérience) est le vrai facteur.
Limite 3 : biais algorithmiques
Un modèle entraîné sur des données historiques reproduit et amplifie les biais présents dans ces données. Exemples : logiciels de recrutement discriminants, outils de reconnaissance faciale moins performants sur certaines peaux.
Limite 4 : opacité (boîte noire)
Les réseaux profonds sont difficiles à interpréter. On ne peut pas toujours expliquer pourquoi un modèle a pris telle décision, ce qui pose problème dans les domaines réglementés (santé, finance, justice). Le champ de l’IA explicable (XAI) tente de répondre à cette limite.
Limite 5 : généralisation hors domaine
Un modèle performant sur son domaine d’entraînement peut échouer catastrophiquement face à une situation légèrement différente. C’est le problème de la généralisation distributionnelle.
IA étroite vs IA générale : L’IA étroite (narrow AI) est spécialisée dans une tâche unique — elle excelle à jouer à StarCraft ou à détecter des cancers, mais ne peut pas faire l’autre. L’IA générale (AGI, Artificial General Intelligence) serait capable d’accomplir n’importe quelle tâche cognitive humaine. Nous n’avons pas d’AGI aujourd’hui.
Pourquoi la donnée structurée est cruciale
Cet article a posé les principes généraux de l’IA. Mais concrètement, d’où viennent les données qui alimentent ces algorithmes ?
La majeure partie des applications IA en entreprise repose sur des données structurées : des tableaux aux colonnes clairement définies (date, client_id, montant, catégorie), stockés dans des bases de données SQL, des entrepôts de données (BigQuery, Snowflake, Redshift) ou des lacs de données (databases, data lakes).
Le rôle du data engineering
Avant même de penser au modèle, il faut :
- Ingérer les données depuis leurs sources (bases opérationnelles, fichiers logs, API)
- Transformer et nettoyer les données (gérer les valeurs manquantes, unifier les formats, corriger les incohérences)
- Stocker efficacement les données pour l’entraînement et l’inférence
- Versionner les jeux de données pour assurer la reproductibilité
- Monitorer la qualité des données en continu
Ces tâches relèvent du data engineering — une discipline tout aussi fondamentale que l’algorithmique pour le succès des projets IA.
Pour aller plus loin : Cet article constitue le point d’entrée théorique. Pour approfondir les aspects techniques de la donnée, consultez notre article sur le data engineering. Pour comprendre comment ces principes s’appliquent au déploiement de modèles, voir notre guide MLOps.
FAQ
Quelle est la différence entre l'IA, le machine learning et le deep learning ?
L'intelligence artificielle (IA) est le domaine large visant à créer des machines capables de simuler l'intelligence humaine. Le machine learning (apprentissage automatique) est un sous-ensemble de l'IA où les systèmes apprennent à partir de données sans être explicitement programmés. Le deep learning (apprentissage profond) est lui-même un sous-ensemble du machine learning, utilisant des réseaux de neurones artificiels à plusieurs couches (profondes) pour traiter des données complexes comme les images, le texte ou la parole.
Qu'est-ce que l'apprentissage supervisé et à quoi sert-il ?
L'apprentissage supervisé est un paradigme où le modèle apprend à partir d'exemples étiquetés, c'est-à-dire des données d'entrée associées à une sortie attendue (la bonne réponse). Le modèle apprend la relation entre l'entrée et la sortie pour prédire sur de nouvelles données non vues. Il est utilisé pour la classification (reconnaissance d'images, détection de spam) et la régression (prévision de prix, estimation de consommation).
Comment fonctionne un réseau de neurones artificiel ?
Un réseau de neurones artificiel s'inspire du cerveau biologique. Il est composé de couches de neurones artificiels interconnectés. Chaque neurone reçoit des signaux d'entrée pondérés, applique une fonction d'activation, et transmet le résultat. L'apprentissage consiste à ajuster les poids des connexions pour que la sortie du réseau se rapproche de la valeur attendue. Un réseau profond (deep learning) comporte plusieurs couches cachées, lui permettant d'apprendre des représentations hiérarchiques.
Qu'est-ce que le gradient et pourquoi est-il fondamental ?
Le gradient est un vecteur qui indique la direction de la plus forte augmentation d'une fonction. En apprentissage automatique, on utilise l'algorithme de descente de gradient pour minimiser l'erreur du modèle : à chaque étape, on calcule le gradient de la fonction d'erreur par rapport aux paramètres du modèle, puis on ajuste les paramètres en sens inverse du gradient (vers la direction de la plus forte diminution de l'erreur). C'est le mécanisme fondamental qui permet aux modèles d'apprendre à partir des données.
Quelles sont les principales limites de l'IA actuelle ?
L'IA actuelle (dite "étroite") présente plusieurs limites : (1) elle nécessite de grandes quantités de données étiquetées, (2) elle manque de bon sens et de compréhension causale, (3) elle est sensible aux biais des données d'entraînement, (4) elle peine à généraliser hors de son domaine d'entraînement, (5) son fonctionnement est souvent opaque (problème de l'"explicabilité"). L'IA ne "comprend" pas au sens humain : elle détecte des régularités statistiques.
Qu'est-ce que le "problème de l'alignement" en IA ?
Le problème de l'alignement (AI alignment) désigne la difficulté à concevoir des systèmes d'IA dont les objectifs sont parfaitement alignés avec les valeurs et intentions humaines. Un système peut apprendre à optimiser la métrique qu'on lui donne (ex. "maximiser les clics") d'une manière qui produit des effets secondaires indésirables (ex. contenu addictif ou trompeur). C'est un enjeu majeur à mesure que les systèmes deviennent plus puissants et autonomes.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
Revenir au guide complet
Cet article fait partie du guide complet sur l’intelligence artificielle qui couvre l’ensemble des concepts, algorithmes et applications de l’IA.
Sources
- Russell, S., & Norvig, P. (2021) – Artificial Intelligence: A Modern Approach (4th ed.)
- Goodfellow, I., Bengio, Y., & Courville, A. (2016) – Deep Learning (MIT Press)
- LeCun, Y., Bengio, Y., & Hinton, G. (2015) – Deep learning, Nature
- Google Cloud (2026) – AI/ML fundamentals
- Bishop, C. (2006) – Pattern Recognition and Machine Learning
- Vanderbilt / Coursera (2025) – Introduction to Artificial Intelligence (AI)
- CNRS (2026) – Le deep learning et ses limites
- Gartner (2026) – AI Hype Cycle: Where are we in 2026?