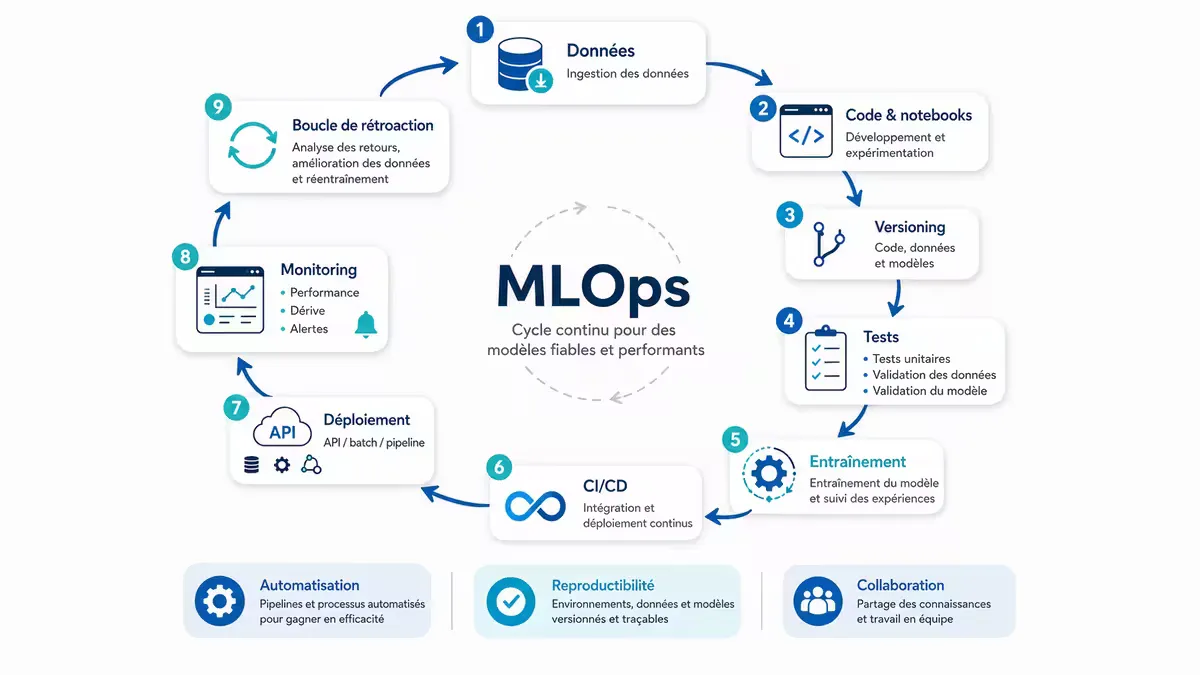
Figure — Cycle MLOps complet : du versioning des données au monitoring en production, en passant par les tests automatisés et le déploiement continu.
Les data scientists savent construire des modèles performants sur leurs notebooks. Mais combien de ces modèles atteignent la production de manière fiable ? Si l’indicateur historique de Gartner estimait que seulement 53 % des projets ML passaient le cap du prototype, la complexification des architectures en 2026 montre que l’écart reste majeur. Cet écart, c’est le MLOps.
Résumé
Ce guide présente les bonnes pratiques DevOps appliquées à la Data Science (MLOps) telles qu’elles émergent des retours d’expérience en 2026. Nous couvrons : (1) les spécificités du MLOps par rapport au DevOps classique, (2) le versioning des données et des modèles avec DVC et MLflow, (3) l’architecture d’un pipeline CI/CD pour ML (tests, validation, déploiement), (4) les stratégies de déploiement sans risque (shadow mode, canary, blue/green), (5) le monitoring multidimensionnel (dérive des données, du concept, opérationnelle), (6) une checklist MLOps pour passer de 0 à 1. Des exemples concrets et des recommandations d’outils jalonnent l’article.
Table des matières
- Pourquoi le DevOps ne suffit pas pour la Data Science
- Les quatre piliers du MLOps
- Versioning des données et des modèles
- Tests automatisés pour pipelines ML
- CI/CD pour modèles : workflow type
- Stratégies de déploiement sans risque
- Monitoring multidimensionnel d’un modèle en production
- Checklist MLOps : du notebook à la production
- Stack MLOps recommandée par taille d’équipe
- FAQ
Pourquoi le DevOps ne suffit pas pour la Data Science
Le DevOps classique excelle dans le déploiement continu d’artefacts déterministes : du code, des configurations, des conteneurs. Une fois déployé, le comportement est connu et stable.
Le Machine Learning ajoute trois complexités fondamentales.
Complexité 1 : les données sont non déterministes
Le code d’entraînement peut être parfait, mais si les données d’entrée changent (nouvelle source, erreur amont, changement de comportement utilisateur), le modèle se dégrade silencieusement.
En DevOps : git commit capture l’état du code.
En MLOps : il faut capturer l’état du code ET des données.
Complexité 2 : la performance est probabiliste et se dégrade
Un modèle à 95 % de précision aujourd’hui peut tomber à 85 % dans trois mois, sans aucun changement de code. La dérive du concept (concept drift) — la relation entre features et cible qui évolue — est une réalité dans tout système dynamique.
En DevOps : l’application marche ou ne marche pas. En MLOps : le modèle “marche moins bien” progressivement. Il faut le détecter avant l’impact métier.
Complexité 3 : l’entraînement est coûteux et long
Tester une nouvelle version d’une application Java prend 5 minutes. Réentraîner un modèle sur 10 To de données prend 8 heures et coûte 500 $.
En DevOps : itérations rapides, tests fréquents. En MLOps : itérations lourdes, besoin de sélection intelligente des candidats à l’entraînement.
MLOps (Machine Learning Operations) : ensemble de pratiques et d’outils visant à automatiser, fiabiliser et maintenir les modèles de machine learning en production, en intégrant les spécificités des données et de l’apprentissage statistique.
Les quatre piliers du MLOps
La littérature et les retours d’expérience convergent vers quatre piliers structurants.
Pilier 1 : Versioning (code, données, modèles)
Tout artefact participant à la production d’une prédiction doit être versionné : le code, les données d’entraînement, les hyperparamètres, les poids du modèle. Sans versioning, pas de reproductibilité, pas de rollback, pas d’audit.
Pilier 2 : Tests automatisés (validation et non-régression)
Avant chaque mise en production, un ensemble de tests doit valider que le nouveau modèle n’est pas moins performant que l’actuel sur des métriques métier, et que les données d’entrée respectent le schéma attendu.
Pilier 3 : CI/CD adapté (déploiement progressif)
Le déploiement d’un modèle ne se fait jamais en “big bang”. Les pratiques de shadow mode, canary et blue/green sont essentielles pour détecter les régressions avant qu’elles n’impactent les utilisateurs.
Pilier 4 : Monitoring multidimensionnel (données, concept, opérations)
La surveillance d’un modèle en production couvre trois dimensions : les données d’entrée (drift), la relation features-cible (concept drift), et les performances système (latence, mémoire).
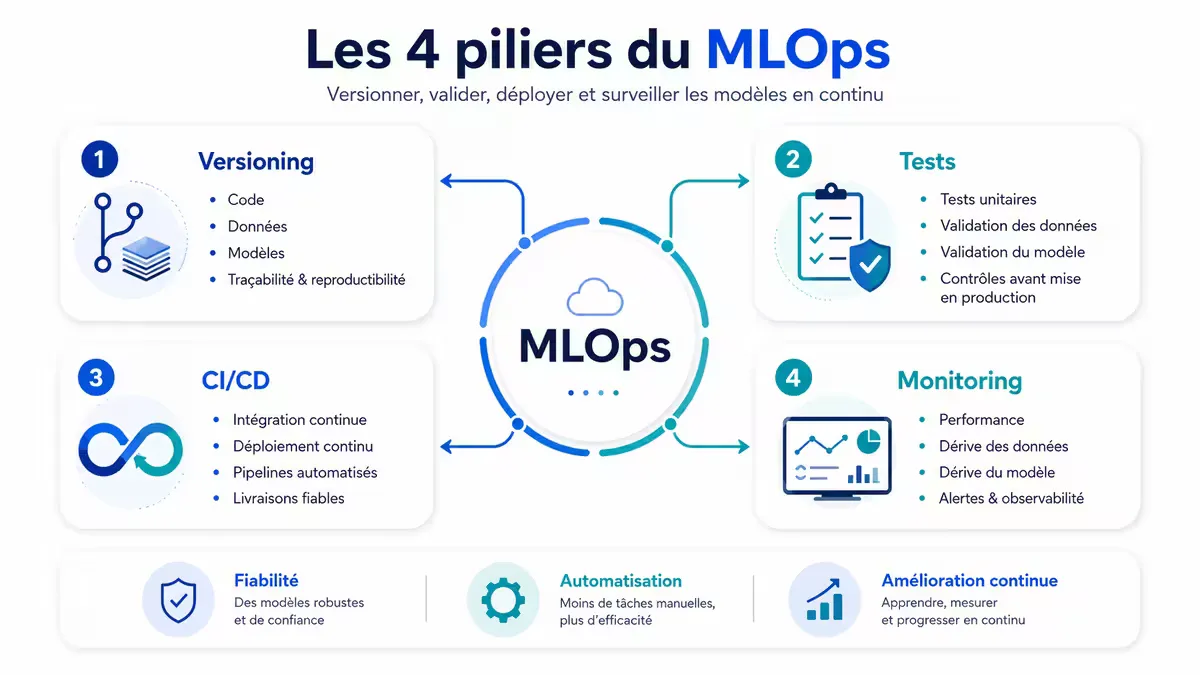
Figure — Les quatre piliers du MLOps, adaptés des frameworks de Google Cloud et de l’IEEE. Ces piliers constituent la base de toute stratégie MLOps robuste.
Versioning des données et des modèles
Versioning des données : au-delà de Git
Git n’est pas conçu pour les fichiers volumineux (quelques Go maximum). Plusieurs solutions existent.
| Outil | Principe | Cas d’usage |
|---|---|---|
| DVC | Métadonnées dans Git, données sur S3/GCS/Azure | Équipes déjà sur Git, besoin de reproductibilité |
| LakeFS | Stockage S3 avec branches (comme Git) | Grandes équipes, besoin d’isolation data science / production |
| Delta Lake | Time travel intégré dans le lakehouse | Écosystème Databricks / Spark |
Bonne pratique : Ne versionnez pas les données brutes. Versionnez les transformations et les échantillons qualifiés qui servent à l’entraînement de référence.
# Initialisation d'un dépôt DVC
dvc init
git commit -m "Initialize DVC"
# Ajout d'un dataset
dvc add data/train.parquet
git add data/train.parquet.dvc .gitignore
git commit -m "Add raw training dataset"
# Pousser les données vers le remote (S3/GCS)
dvc remote add -d myremote s3://mybucket/dvcstore
dvc pushVersioning des modèles : MLflow Model Registry
MLflow est devenu le standard de facto pour le tracking et le versioning des modèles.
import mlflow
from mlflow.tracking import MlflowClient
client = MlflowClient()
# Création d'une nouvelle version du modèle
client.create_model_version(
name="customer_churn_model",
source="gs://models/churn/v2.3/",
run_id="e3d5a1b2c4f6",
description="XGBoost avec feature engineering v3"
)
# Transition d'une version à "Staging"
client.transition_model_version_stage(
name="customer_churn_model",
version=5,
stage="Staging"
)L’importance du hash de reproductibilité
La reproductibilité en ML repose sur la combinaison (code hash + data hash + params hash). Un seul changement déclenche un nouvel artefact.
# reproducible_hash.yaml
code_version: a3f5c91
dataset_version: 2026-06-01_train_v2
params:
learning_rate: 0.01
max_depth: 7
model_artifact: gs://models/churn/2026-06-06/
resulting_metric: f1=0.89Tests automatisés pour pipelines ML
Les quatre familles de tests
Avant même de lancer l’entraînement : schéma attendu (types, colonnes), distribution des valeurs (min/max, valeurs manquantes < seuil), détection d’anomalies grossières. Outils : Great Expectations, Pydantic, TensorFlow Data Validation (TFDV).
Chaque fonction de preprocessing, chaque transformation, chaque métrique personnalisée doit avoir son test unitaire. À exécuter sur un sous-ensemble minimal (100 lignes).
Sanity checks : le modèle bat-il une baseline aléatoire (50% ?). Régression sur échantillon gelé : la performance sur un dataset de référence ne doit pas baisser de plus de 2 %.
Le endpoint répond-il ? La latence est-elle compatible avec le SLA ? Le format de réponse est-il correct ? Charge test (ex. 100 req/s) pour valider le scaling.
Exemple : validation des données avec Great Expectations
import great_expectations as ge
# Chargement du DataFrame d'entrée
df = ge.read_parquet("gs://input/inference_batch.parquet")
# Validation du schéma et des contraintes
validation_results = df.expect_column_values_to_not_be_null("user_id")
validation_results = df.expect_column_values_to_be_between("age", 0, 120)
validation_results = df.expect_column_values_to_be_in_set("country", ["FR", "BE", "CH"])
# Si échec, déclencher alerte et bloquer l'inférence
if not validation_results.success:
raise ValueError(f"Data validation failed: {validation_results}")CI/CD pour modèles : workflow type
Un pipeline CI/CD pour ML suit généralement cette séquence.
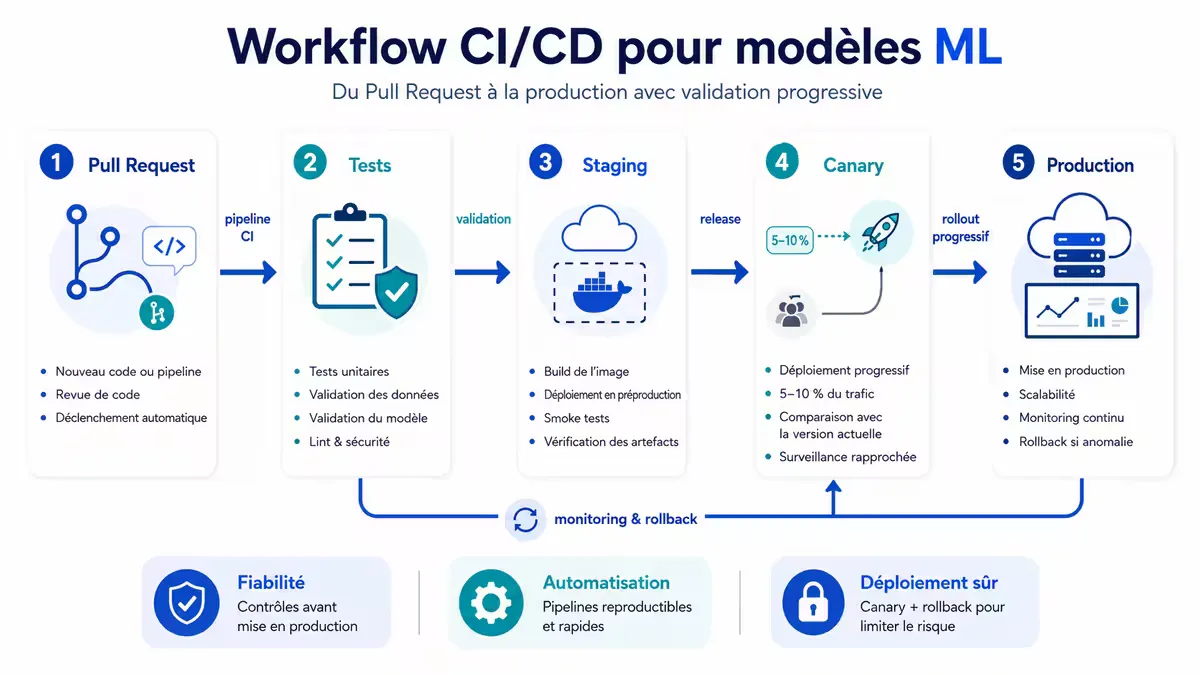
Figure — Workflow CI/CD typique pour un modèle ML, inspiré des pratiques de Google Cloud et Uber. La validation humaine reste présente au niveau de la promotion en production.
name: MLOps Pipeline
on:
push:
branches: [main]
pull_request:
branches: [main]
jobs:
test-light:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Run data validation (sample)
run: python tests/test_data_validation.py --sample 1000
- name: Run unit tests
run: pytest tests/unit/
train-and-register:
needs: test-light
if: github.event_name == 'push' && github.ref == 'refs/heads/main'
runs-on: [self-hosted, gpu]
steps:
- name: Full training
run: python train.py --full-data --model-version ${{ github.sha }}
- name: Evaluate vs baseline
run: python tests/check_regression.py --threshold 0.02
- name: Register to MLflow
run: python scripts/mlflow_register.py --stage Staging
deploy-staging:
needs: train-and-register
runs-on: ubuntu-latest
steps:
- name: Deploy to staging endpoint
run: python scripts/deploy.py --env staging --traffic 0
- name: Validate staging (shadow mode)
run: python tests/validate_staging.py --duration 3600
promote-to-prod:
needs: deploy-staging
runs-on: ubuntu-latest
environment: production
steps:
- name: Canary 5% traffic
run: python scripts/deploy.py --env prod --traffic 5
- name: Monitor canary
run: python tests/monitor_canary.py --duration 7200 --alert-threshold 0.01
- name: Full rollout
run: python scripts/deploy.py --env prod --traffic 100Rôle de l’ingénieur MLOps : Contrairement au DevOps classique où la promotion applicative peut être automatisée à 100 %, en MLOps, un ingénieur MLOps (ou un Machine Learning Engineer senior) valide souvent de manière finale les métriques du nouveau modèle avant sa bascule complète. L’humain reste dans la boucle pour les décisions métiers à fort impact.
Stratégies de déploiement sans risque
Stratégie 1 : Shadow mode (mode ombre)
Le nouveau modèle tourne en parallèle de l’ancien, mais ses prédictions ne sont pas servies aux utilisateurs. On compare les deux sorties pendant plusieurs jours pour détecter des comportements aberrants.
# Principe du shadow mode
def shadow_inference(request):
prediction_old = model_old.predict(request)
prediction_new = model_new.predict(request)
# Log des divergences pour analyse
if abs(prediction_new - prediction_old) > threshold:
log_divergence(request, prediction_old, prediction_new)
# Seule l'ancienne version répond
return prediction_oldStratégie 2 : Canary deployment
5 à 10 % du trafic est dirigé vers le nouveau modèle. Surveillance renforcée pendant 24 à 48 heures. Si aucune alerte, augmentation progressive à 25 %, 50 %, 100 %.
# Principe du canary (routage aléatoire)
def canary_inference(request):
if random.random() < 0.05: # 5% de trafic canary
return model_new.predict(request)
else:
return model_old.predict(request)Stratégie 3 : Blue/Green deployment
Deux environnements identiques (blue = production actuelle, green = nouvelle version). Après validation du green, bascule du routeur (load balancer) du blue vers le green en une fois. Rollback : rebascule immédiate.
Avantage : bascule instantanée, pas de code gérant deux versions. Inconvénient : double infrastructure pendant la validation.
Stratégie 4 : Automated rollback conditionnel
Des métriques de santé (latence p99, taux d’erreur, métrique métier échantillonnée) sont surveillées en continu. Si un seuil critique est dépassé, le système bascule automatiquement vers la version précédente.
if (
latency_p99 > 2000 # ms
or error_rate > 0.05
or sampled_accuracy < baseline_accuracy - 0.02
):
rollback_to_previous_version()
alert_oncall_engineer()À retenir : Ne déployez jamais un modèle en big bang. Commencez par le shadow mode pour valider sans risque. Passez au canary pour les modèles à trafic modéré. Réservez le blue/green aux applications critiques nécessitant une bascule immédiate. L’automated rollback est indispensable dès que vous passez en canary ou blue/green.
Monitoring multidimensionnel d’un modèle en production
Dimension 1 : Dérive des données (Data drift)
La distribution des features d’entrée change par rapport au jeu d’entraînement.
À surveiller : distribution de chaque feature (PSI - Population Stability Index), valeurs manquantes, valeurs hors domaine.
Seuil typique : alerte si PSI > 0.15 (significatif) ou > 0.25 (alerte critique).
Dimension 2 : Dérive du concept (Concept drift)
La relation entre les features et la cible évolue. Plus difficile à détecter car nécessite la vérité terrain (qui arrive avec délai).
À surveiller : performance réelle sur échantillon annoté, confusion matrix, lift sur sous-populations.
Dimension 3 : Dérive opérationnelle
Les performances système se dégradent.
À surveiller : latence p50/p95/p99, taux d’erreur (4xx, 5xx), utilisation CPU/GPU, mémoire.
Implémentation de référence
# Configuration du monitoring sur Vertex AI
from google.cloud import aiplatform
endpoint = aiplatform.Endpoint(endpoint_id="churn_endpoint")
endpoint.deploy(
model=model,
monitoring_config={
"enable_data_drift_detection": True,
"drift_threshold": 0.15,
"sampling_rate": 0.1, # 10% des prédictions échantillonnées
"alert_webhook": "https://hooks.slack.com/..."
}
)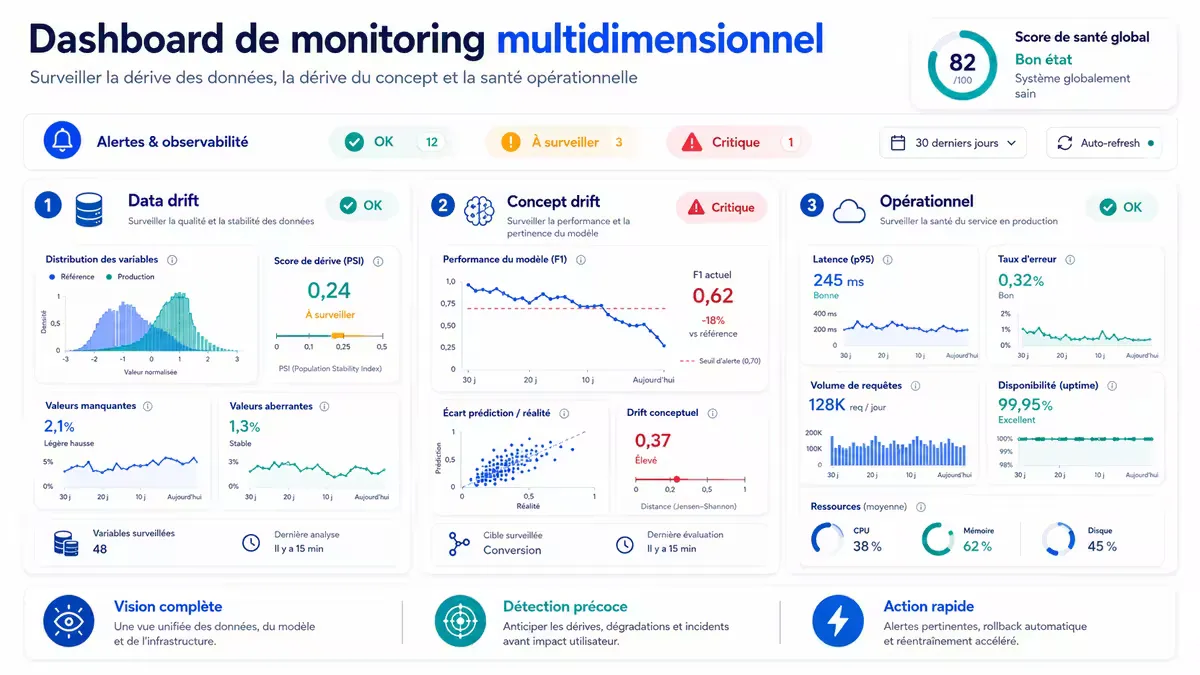
Figure — Dashboard de monitoring multidimensionnel pour un modèle en production. La détection précoce de la dérive permet un réentraînement avant l’impact métier.
Checklist MLOps : du notebook à la production
Voici une checklist progressive pour faire passer un modèle de l’expérimentation à la production.
Phase 1 : Fondations (score 0 → 1)
- Le code d’entraînement est versionné dans Git
- Les données d’entraînement sont versionnées (DVC ou LakeFS)
- Les hyperparamètres sont explicitement enregistrés
- Un notebook de reproductibilité existe (chaque cellule est exécutable)
- Le modèle exporté est reproductible (hash code + data + params)
Phase 2 : Tests et validation (score 1 → 2)
- Validation du schéma des données d’entrée (Great Expectations)
- Tests unitaires sur les fonctions de preprocessing
- Test de non-régression sur un échantillon gelé
- Le modèle bat une baseline simple (random, moyenne)
- La documentation du modèle (intention d’usage, limites) est écrite
Phase 3 : CI/CD (score 2 → 3)
- Pipeline CI déclenché sur chaque PR (tests légers)
- Pipeline CD déclenché sur merge main (entraînement complet)
- MLflow Model Registry avec étapes Staging → Production
- Validation finale par un ingénieur MLOps ou un MLE senior avant promotion
- Rollback automatisé sur détection d’anomalie opérationnelle ou de performance
Phase 4 : Production robuste (score 3 → 4)
- Monitoring des données (data drift) et alerting
- Monitoring de la performance dès que la vérité terrain arrive
- Déploiement en canary (5% → 100%) avec automated rollback
- SLA de latence documenté et surveillé
- Plan de réentraînement documenté (fréquence, déclenchement)
Bonnes pratiques pour commencer : N’essayez pas de tout implémenter en une fois. Commencez par la Phase 1 (versioning) sur votre prochain modèle. Ajoutez les tests de validation (Phase 2) une fois le versioning stable. La CI/CD (Phase 3) vient ensuite. La majorité des équipes s’arrêtent à la Phase 3, ce qui est déjà un excellent niveau.
Stack MLOps recommandée par taille d’équipe
Petite équipe (2-5 data scientists, < 5 modèles en prod)
| Couche | Outil | Pourquoi |
|---|---|---|
| Versioning données | DVC | Léger, s’intègre à Git |
| Tracking & Registry | MLflow | Standard, facile à installer |
| CI/CD | GitHub Actions / GitLab CI | Intégré à Git |
| Orchestration | Prefect ou Dagster | Plus simple qu’Airflow |
| Monitoring | Evidently AI + Slack | Open source, bonne couverture |
Équipe moyenne (5-20 data scientists, 5-50 modèles)
| Couche | Outil | Pourquoi |
|---|---|---|
| Versioning données | LakeFS ou Delta Lake | Branches data science / prod |
| Tracking & Registry | MLflow + Model Registry | Passe à l’échelle |
| Feature Store | Feast (open source) | Partage de features entre équipes |
| Orchestration | Airflow (Cloud Composer) | Maturité, écosystème large |
| Monitoring | Vertex AI / SageMaker / Azure ML | Natif au cloud |
| Pipelines CI/CD | Jenkins + Spinnaker | Gouvernance enterprise |
Grande entreprise (>20 data scientists, >50 modèles)
| Couche | Outil | Pourquoi |
|---|---|---|
| Plateforme | Vertex AI / SageMaker / Azure ML | Intégration native, support enterprise |
| Feature Store | Natif au cloud | Performance, gouvernance |
| CI/CD | GitLab + ArgoCD | GitOps pour ML |
| Monitoring | Datadog + plateforme cloud | Observabilité unifiée |
| Orchestration | Kubeflow + Airflow | Flexibilité maximale |
Les organisations ayant déjà investi dans les plateformes MLOps comparées bénéficient d’outils natifs réduisant la fragmentation.
FAQ
Quelle est la différence entre DevOps et MLOps ?
Le DevOps classique gère des artefacts déterministes (code, configuration). Le MLOps ajoute trois complexités : (1) les données versionnées (non déterministes, volumineuses), (2) les modèles (performance qui se dégrade, reproductibilité complexe), (3) le monitoring multidimensionnel (dérive des données, dérive du concept, dérive opérationnelle). Le MLOps étend le DevOps avec des étapes spécifiques : validation des données, tracking des expériences, détection de dérive.
Comment versionner des datasets volumineux (plusieurs To) ?
Les outils VCS classiques (Git) ne passent pas à l'échelle. Utilisez des solutions dédiées : DVC (Data Version Control) qui stocke les métadonnées dans Git et les données sur S3/GCS/Azure, LakeFS (stockage de type S3 avec branches), ou Delta Lake (Time Travel intégré). La bonne pratique est de versionner non pas les données brutes (trop lourdes) mais les transformations et les échantillons qualifiés.
Quels tests automatisés pour un pipeline ML ?
Quatre catégories : (1) tests de validation des données (schema, distributions, valeurs manquantes) avant entraînement, (2) tests du code d'entraînement (unitaires sur les fonctions de preprocessing, intégration sur la boucle d'entraînement), (3) tests du modèle (sanity checks : meilleur qu'une baseline aléatoire, performance sur échantillon fixe), (4) tests de l'API d'inférence (latence, format réponse). Les tests de non-régression sur métriques métier sont essentiels avant tout déploiement.
Comment organiser un workflow CI/CD pour un modèle ML ?
Un workflow typique : (1) PR déclenche tests unitaires + validation schéma données sur échantillon, (2) merge sur main déclenche entraînement complet + registre des métriques, (3) si métriques > seuil, création modèle candidat, (4) déploiement en staging (validation A/B ou shadow mode), (5) promotion en production après validation manuelle ou automatique. Le release engineer valide avant déploiement final. Le déploiement blue/green ou canary est recommandé.
Quels outils MLOps pour une petite équipe (5-10 data scientists) ?
MLflow (tracking, model registry, déploiement basique) associé à DVC (versioning données) et GitHub Actions (CI/CD). C'est une stack légère, open source, bien documentée. Pour l'orchestration des pipelines, préférez une solution simple (Prefect, Dagster) plutôt qu'Airflow (plus lourd à maintenir). Évitez de sur-architecturer : commencez par automatiser la validation des données et le déploiement staging avant de complexifier.
Comment faire du déploiement continu en ML (CD) sans risque ?
Le déploiement continu en ML ne doit jamais être entièrement automatique. Utilisez des garde-fous : (1) shadow mode : le nouveau modèle tourne en parallèle sans servir de trafic, comparez ses prédictions avec l'ancien (2) canary deployment : 5 % du trafic, monitoring rapproché pendant 24h (3) automated rollback : si latence p95 > seuil ou métrique métier dégradée, retour auto à la version précédente. La validation humaine sur une période d'observation reste recommandée pour les modèles à fort impact.
Articles connexes
Pour approfondir les sujets abordés dans cet article :
Revenir au guide complet
Cet article fait partie du guide complet sur le Data Engineering qui couvre l’ensemble des architectures, outils et bonnes pratiques pour la mise en production des données et des modèles.
Sources
- Gartner (2025) – Why 53% of ML projects fail to deploy
- Google Cloud (2026) – MLOps best practices: From notebook to production
- Uber Engineering (2025) – Michelangelo: MLOps at scale
- IEEE Software (janvier 2026) – Continuous delivery for machine learning
- McKinsey & Company (2026) – The state of MLOps adoption 2026
- Great Expectations (2026) – Data validation for ML pipelines
- MLflow (2026) – Model Registry documentation
- DVC (2026) – Data version control best practices