Le deep learning atteint des sommets de performance, mais personne ne comprend vraiment comment il fonctionne. Un paradoxe qui devient un problème majeur.
Résumé
Le deep learning a révolutionné l’IA : reconnaissance d’images, diagnostic médical, traduction automatique… Pourtant, ces modèles restent largement opaques, même pour leurs créateurs. Ce « paradoxe de la boîte noire » pose des défis éthiques, juridiques et opérationnels : comment faire confiance à un modèle qu’on ne comprend pas ? Comment le rendre responsable en cas d’erreur ? Cet article explore les causes de l’opacité (complexité, non‑linéarité, millions de paramètres), les domaines où elle est critique (santé, finance, justice), et les pistes pour une IA explicable (XAI) : LIME, SHAP, cartes de saillance, architectures interprétables.
Table des matières
- Le paradoxe en une image
- Pourquoi les réseaux de neurones sont-ils des boîtes noires ?
- Pourquoi ce paradoxe est-il un problème ?
- Domaines critiques : quand l’opacité devient dangereuse
- Vers une IA explicable (XAI)
- Le compromis : performance vs explicabilité
- Conclusion : faut-il abandonner le deep learning ?
- FAQ
1. Le paradoxe en une image

Figure 1 — Le réseau de neurones profond : des entrées, des sorties, mais les couches internes restent largement incompréhensibles.
Le paradoxe est simple : nous savons construire des modèles de deep learning très performants, mais nous ne savons pas pourquoi ils prennent leurs décisions. Un réseau de neurones peut reconnaître un chat sur une photo avec 99 % de précision, mais il est incapable d’expliquer qu’il s’est basé sur les oreilles pointues, les moustaches ou la texture de la fourrure.
2. Pourquoi les réseaux de neurones sont-ils des boîtes noires ?
2.1 – Le nombre astronomique de paramètres
Un réseau de neurones profond (ex: ResNet-152) a des millions, voire des milliards de poids. Chaque poids interagit avec les autres de manière non linéaire. Il est humainement impossible de suivre le flux d’information.
2.2 – La non‑linéarité
Les fonctions d’activation (ReLU, sigmoïde, tanh) introduisent des non‑linéarités à chaque couche. Le comportement global est une composition complexe de ces non‑linéarités, sans forme analytique simple.
2.3 – L’émergence de représentations
Les couches internes apprennent des représentations hiérarchiques (bords → textures → formes → objets). Mais ces représentations sont des vecteurs de nombres flottants, pas des concepts symboliques que l’humain comprend naturellement.
2.4 – L’entraînement stochastique
L’optimisation par descente de gradient stochastique (SGD) trouve une solution, mais pas nécessairement la solution la plus simple ou la plus interprétable. Deux entraînements différents peuvent produire des réseaux très différents pour la même performance.
3. Pourquoi ce paradoxe est-il un problème ?
| Problème | Conséquence |
|---|---|
| Responsabilité légale | Si un modèle cause un préjudice (diagnostic erroné, refus de crédit injuste), qui est responsable ? Le développeur, l’utilisateur, le modèle ? L’absence d’explication bloque l’attribution des responsabilités. |
| Confiance | Les utilisateurs finaux (médecins, juges, clients) refusent d’utiliser un outil dont ils ne comprennent pas le raisonnement, surtout quand les enjeux sont vitaux. |
| Détection des biais | Un modèle peut apprendre des biais discriminatoires (race, genre, âge). Sans explication, il est très difficile de détecter ces biais et de les corriger. |
| Robustesse | On ne sait pas pourquoi un modèle échoue sur certains exemples (ex: « adversarial examples » où une image légèrement modifiée est classée complètement différemment). L’opacité empêche de renforcer la robustesse. |
| Amélioration | Comment améliorer un modèle si on ne comprend pas ses faiblesses ? L’ingénierie heuristique (ajouter des données, augmenter les couches) est coûteuse et aveugle. |
4. Domaines critiques : quand l’opacité devient dangereuse
Santé
Un modèle de deep learning peut détecter un cancer sur une radiographie mieux qu’un radiologue. Mais s’il se trompe, le médecin doit savoir pourquoi pour ne pas reproduire l’erreur. Les explications peuvent aussi révéler des biais (ex: le modèle s’appuie sur la marque du scanner, pas sur la tumeur).
Finance
Les banques utilisent des modèles pour accorder des crédits. Le RGPD (et bientôt l’AI Act) impose un droit à l’explication : une personne refusée doit savoir pourquoi. Un modèle boîte noire est illégal dans ce contexte.
Justice
Des algorithmes prédictifs de récidive (ex: COMPAS aux États-Unis) ont été accusés de biais raciaux. Faute d’explications, il est impossible de prouver ou d’infirmer ces accusations.
Recrutement
Des outils de filtrage de CV peuvent discriminer involontairement (genre, âge, origine). L’opacité empêche les entreprises de se conformer aux lois sur l’égalité des chances.
Véhicules autonomes
Si une voiture autonome cause un accident, il faut comprendre pourquoi (erreur de perception, mauvaise décision, dysfonctionnement). Sans explicabilité, la responsabilité est impossible à établir.
5. Vers une IA explicable (XAI)
Le domaine de l’IA explicable (Explainable AI, XAI) propose des méthodes pour ouvrir la boîte noire.
Méthodes post-hoc (après entraînement)
- LIME (Local Interpretable Model-agnostic Explanations) : on perturbe localement l’entrée et on observe l’impact sur la sortie. On construit un modèle linéaire interprétable localement.
- SHAP (SHapley Additive exPlanations) : basé sur la théorie des jeux, attribue à chaque variable une « importance » pour la prédiction.
- Cartes de saillance : pour les images, on calcule le gradient de la sortie par rapport aux pixels pour visualiser les zones importantes.
- Attention : dans les transformers, les poids d’attention montrent quels tokens ont été « regardés » pour produire la sortie.
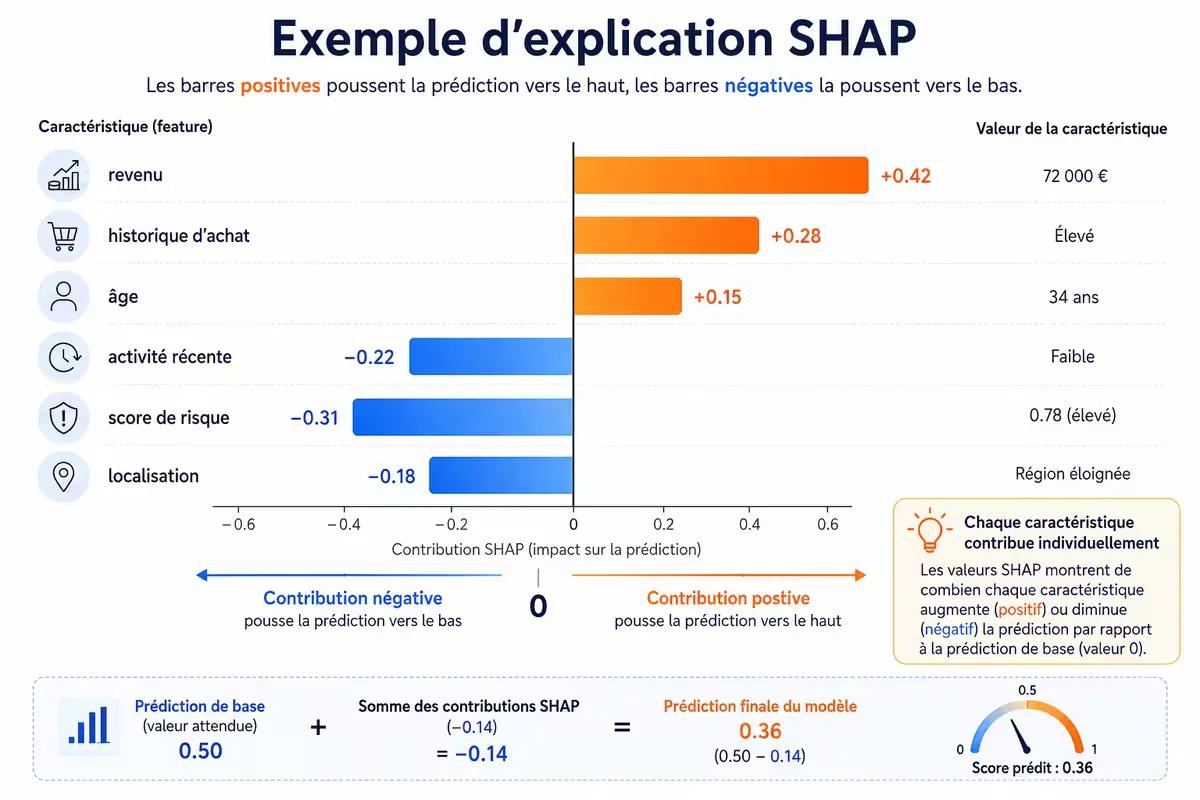
Figure 2 — Exemple d’explication SHAP pour une prédiction de crédit : chaque variable (âge, revenu, etc.) contribue positivement ou négativement au score.
Méthodes intrinsèques (architectures interprétables)
- Réseaux prototypiques : le modèle apprend des prototypes (exemples typiques) et compare la nouvelle donnée aux prototypes.
- Concept bottleneck models : on force le modèle à prédire des concepts compréhensibles (ex: « a-t-il des ailes ? ») avant la décision finale.
- Arbres de décision profonds (ex: NBDT) : on contraint le réseau à imiter un arbre de décision.
Limites des méthodes XAI
- Fidélité : l’explication est-elle fidèle au vrai fonctionnement du modèle ? On ne le sait jamais vraiment.
- Stabilité : des explications très différentes pour des entrées très proches.
- Coût : certaines méthodes (SHAP) sont très coûteuses en calcul.
- Acceptation : les explications restent souvent techniques (gradients, valeurs Shapley), peu compréhensibles par les utilisateurs finaux.
6. Le compromis : performance vs explicabilité
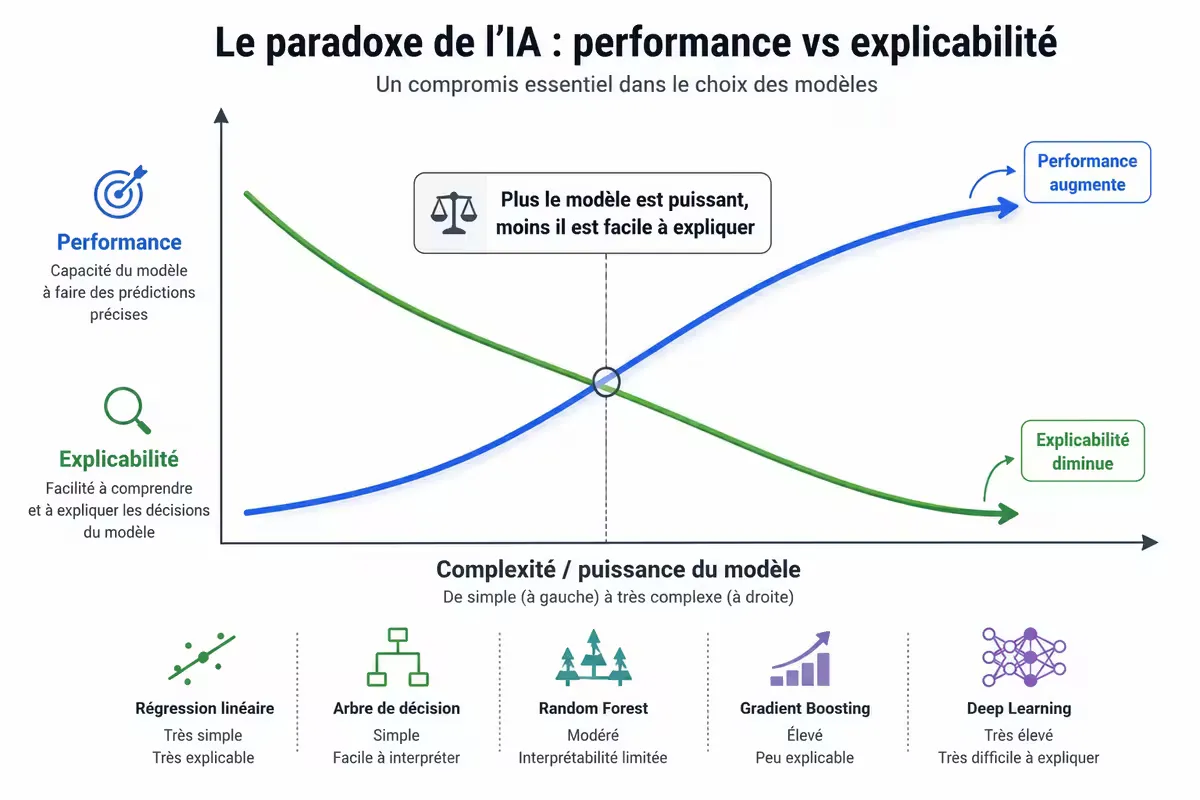
Figure 3 — Le compromis performance / explicabilité. Le deep learning maximise la performance au prix de l’opacité.
| Modèle | Performance (données complexes) | Explicabilité |
|---|---|---|
| Régression logistique | Faible | Très élevée |
| Arbre de décision (faible profondeur) | Moyenne | Élevée |
| Forêt aléatoire | Bonne | Faible |
| SVM avec noyau | Bonne | Très faible |
| Deep learning (CNN, RNN, Transformers) | Très élevée | Extrêmement faible |
Le dilemme : dans les domaines critiques (santé, finance, justice), on a besoin à la fois de performance et d’explicabilité. Le deep learning pur est souvent inacceptable. Les solutions hybrides ou l’utilisation de XAI sont des palliatifs, pas des solutions définitives.
7. Conclusion : faut-il abandonner le deep learning ?
Non. Le deep learning est un outil trop puissant pour être abandonné. Mais il faut l’utiliser avec conscience de ses limites.
- Pour les applications non critiques (recommandation de produits, classification de photos), l’opacité est acceptable.
- Pour les domaines critiques, on doit :
- Utiliser des modèles interprétables par conception quand possible.
- Ajouter une couche d’explicabilité (XAI) et valider que les explications sont fidèles.
- Mettre en place une supervision humaine pour les décisions à fort enjeu.
- Documenter les biais potentiels et les limites.
L’AI Act européen (entrée en vigueur progressive 2025-2027) classe certains usages de l’IA comme « haut risque » (santé, emploi, crédit, justice). Pour ces usages, l’explicabilité est une obligation légale, pas une option. Le paradoxe du deep learning n’est pas qu’un problème technique : c’est un enjeu démocratique.
À retenir : Le deep learning nous donne des prédictions extraordinaires, mais sans compréhension. La prochaine frontière n’est pas plus de couches ou plus de données, mais des modèles à la fois puissants et compréhensibles.
Revenir au guide complet
Cet article fait partie du guide complet sur l’intelligence artificielle qui couvre les concepts, modèles et enjeux éthiques.
Articles connexes
FAQ
Qu’est-ce que le paradoxe du deep learning ?
Le paradoxe est le suivant : les modèles de deep learning (réseaux de neurones profonds) atteignent des performances supérieures aux humains sur de nombreuses tâches (reconnaissance d’images, traduction, diagnostic médical), mais leur fonctionnement interne est largement incompréhensible, même pour leurs concepteurs. On sait qu’ils marchent, mais pas vraiment pourquoi.
Pourquoi les réseaux de neurones sont-ils qualifiés de « boîtes noires » ?
Un réseau de neurones profond contient des millions, voire des milliards de paramètres (poids) répartis sur des dizaines de couches. Chaque couche transforme les données de manière non linéaire. Il est impossible pour un humain de suivre le cheminement d’une donnée à travers toutes ces opérations et de comprendre pourquoi une sortie précise est produite. C’est une « boîte noire ».
En quoi l’opacité du deep learning est-elle problématique ?
Dans des domaines sensibles (santé, finance, justice, recrutement), on ne peut pas se contenter d’une réponse. Un médecin doit savoir pourquoi un modèle a diagnostiqué un cancer. Un juge doit comprendre pourquoi un algorithme recommande une libération conditionnelle. L’absence d’explication bloque la confiance, la responsabilité légale et la détection des biais.
Qu’est-ce que l’IA explicable (XAI) ?
L’IA explicable (Explainable AI, XAI) est un domaine de recherche qui vise à créer des modèles ou des méthodes capables d’expliquer leurs décisions de manière compréhensible par l’humain. Des techniques comme LIME, SHAP, les cartes de saillance ou l’attention visualisent les zones d’une image ou les variables qui ont le plus influencé la prédiction.
Peut-on faire du deep learning totalement explicable ?
C’est un compromis. Les modèles totalement transparents (arbres de décision, régressions logistiques) sont souvent moins performants sur des données complexes. Les modèles de deep learning sont plus puissants mais opaques. La recherche explore des architectures intrinsèquement plus interprétables (concept bottleneck models, réseaux prototypiques) ou des explications post-hoc. Il n’y a pas de solution miracle.
Les modèles récents (GPT-5, Gemini) sont-ils plus explicables ?
Non, ils sont encore plus opaques. Les grands modèles de langage ont des centaines de milliards de paramètres. Les techniques d’explicabilité pour LLM (ex: traçage des tokens attention, mécanismes d’activation) sont très limitées. Le paradoxe s’aggrave avec l’augmentation de la taille des modèles.
Sources
- DARPA (2016) – Explainable AI (XAI) program
- Ribeiro, M. T. et al. (2016) – ”Why Should I Trust You?” Explaining Predictions of Any Classifier (LIME)
- Lundberg, S. & Lee, S.-I. (2017) – A Unified Approach to Interpreting Model Predictions (SHAP)
- European Commission (2024) – AI Act: High-risk AI systems requirements
- Samek, W. et al. (2021) – Explainable AI: Interpreting, Explaining and Visualizing Deep Learning
- Rudin, C. (2019) – Stop explaining black box machine learning models for high stakes decisions
Article mis à jour le 30 mai 2026.